


En esta ocasion hablaremos del lenguaje de programación mas utilizado del mundo, exacto me refiero a SQL, realizaremos todo un curso completo desde cero y explicaremos todo lo necesario para que puedas dominarlo en su totalidad, asi que comenzemos ya que debes aprenderlo ahora mismo!.
QUE ES SQL? #
Como mencionamos anteriormente SQL es un lenguaje de programación, como?, si es un lenguaje de programación y nos sirve para almacenar y procesar información en una base de datos relacional.
Pero que es una base de datos relaciona?
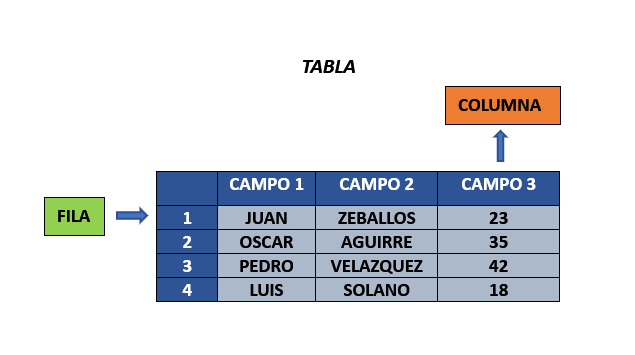
Pues una base de datos relacional almacena información en forma de tabla, con filas y columnas que representan diferentes atributos de datos y las diversas relaciones entre los valores de datos.
POR QUE DEBO APRENDER SQL? #
Es necesario aprenderlo ya que es un lenguaje de consulta popular que se usa con frecuencia en todos los tipos de aplicaciones. Los analistas y desarrolladores de datos aprenden y usan SQL porque se integra bien con los diferentes lenguajes de programación.
INDICE Y ESTRUCTURA
- Que es SQL
- Por que debo aprender SQL?
- Tipos de Bases de datos SQL
- Instalación
- Crear Base de Datos - CREATE DATABASE
- Crear Tabla - CREATE TABLE
- Consultas o Querys
- Instrucción SELECT
- Modificar Tabla - ALTER TABLE
- Instrucción DROP
- Identificadores
- Claves Primarias - PRIMARY KEYS
- Instrucción DELETE
- Claves Foraneas - FOREIGN KEYS
- Clausula AS o ALIAS
- Clausula ORDER BY
- Clausula WHERE
- Instrucción UPDATE
- Operadores en SQL
- Comentario en SQL
- Comentar una linea
- Comentar varias lineas
- Funciones de Agregación
- Clausula GROUP BY
- Clausula HAVING
- Subconsultas
- JOINS
- Clausula UNION
- Clausula UNION ALL
- Indices
- Vistas
- Bloqueos
- Transacciones - BEGIN TRANSACTION
- Procedimientos Almancenados
- SQL y Python
TIPOS DE BASES DE DATOS SQL #
Existen muchos tipos de gestores de bases de datos sql, pero afortunadamente, la mayoría son muy parecidos y la lógica es la misma. Tienen alguna que otra sentencia diferente, pero por lo general, aprender un tipo de SQL te permitirá manejar cualquiera de las otras.
En este caso concreto para el curso usaremos Sqlite ya que este es el gestor de uso mas comun y es compatible con muchos lenguajes de programación y ademas no tiene servidor de base da datos dedicado para poder ejecutarlo y esta integrado directamente con la aplicación lo que nos facilita su uso.
INSTALACIÓN #
La instalación es super sencilla solo debemos ir a la pagina oficial de sqlite para ello aqui dejo el enlace:
Para este caso ya que lo instalación lo hare en windows, una vez estemos en el enlace debemos descargarnos el archivo de nombre sqlite-tools-win32-x86-3420000.zip. Seguidamente lo descomprimimos y copiamos el contenido en una carpeta creada en la raiz de nuestro disco C:.
Seguidamente lo que haremos sera ir a nuestro buscador y buscar Editar las variables del Entorno del Sistema y se nos abrira la siguente ventana:
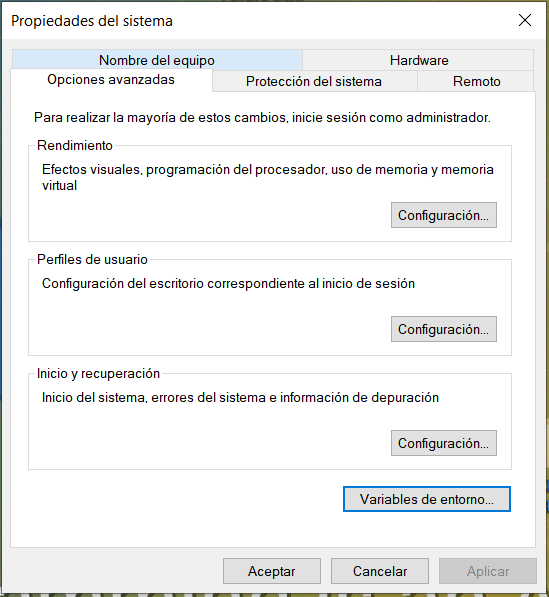
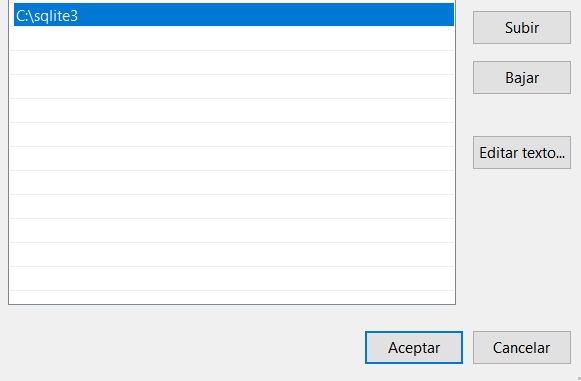
Ahora debemos darle a Variables de Entorno > Path > Editar > Nuevo y pegaremos la ruta de nuestra carpeta donde descomprimimos los archivos y guardamos.
Despues iremos al siguente enlace y descargemos DB Browser for SQLite - Standard installer, dependiendo la version de windows que utilizamos 32 o 64 bits:
Finalmente solo debemos seguir los pasos simples de instalación:
y ya tendriamos sqlite listo para usarlo, damos click en el dbBrowser y se nos abrira la ventana donde vamos a trabajar.
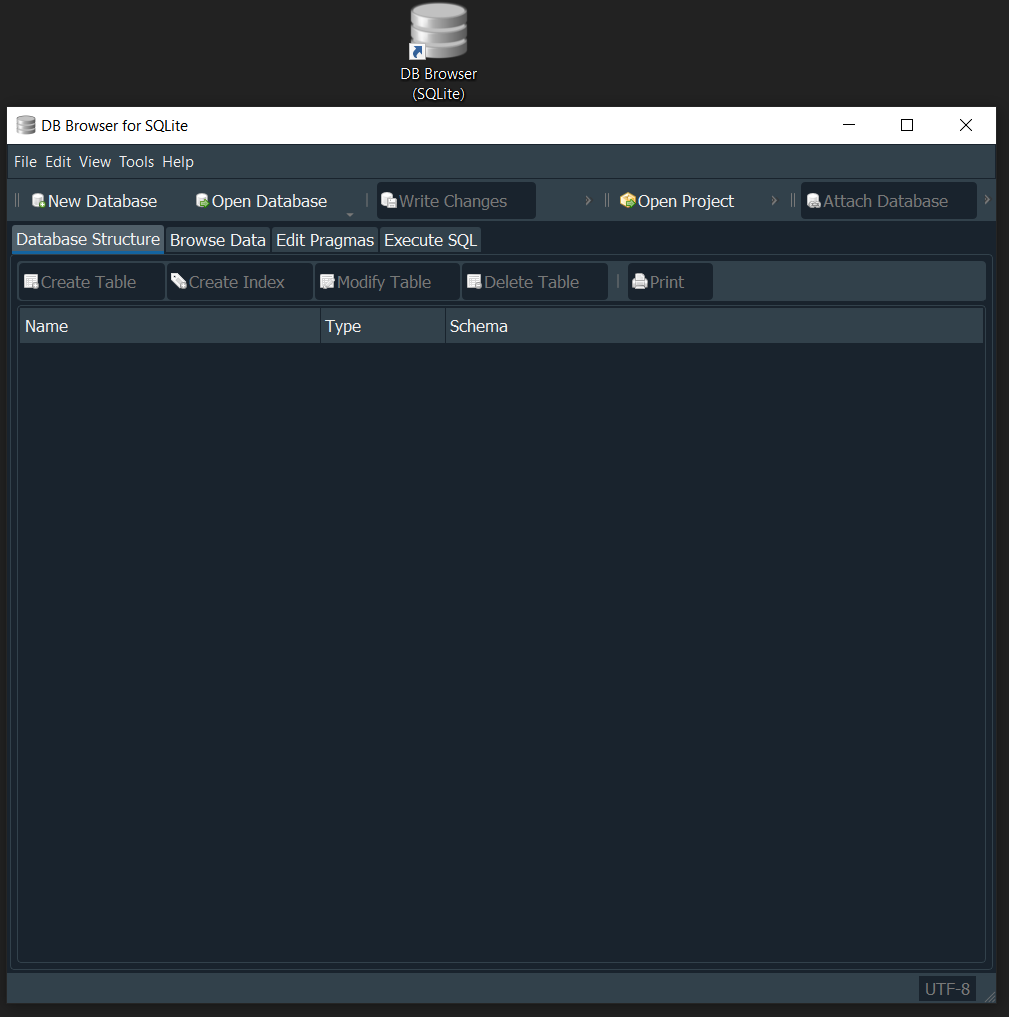
CREAR BASE DE DATOS - CREATE DATABASE #
Para comenzar a crear nuestra primera base de datos en sqlite, podemos hacerlo de dos maneras:
La primera seria simplemente ejecutar la palabra reservada CREATE DATABASE y seguidamente el nombre que queremos que tenga nuestra base de datos, en este caso Alumnos.
CREATE DATABASE Alumnos;
Pero para reprensentarlo de una manera mas visible podemos hacerlo ejecutando en la opcion New Database y le asignamos un nombre, en este caso valga la redundancia Alumnos.db.
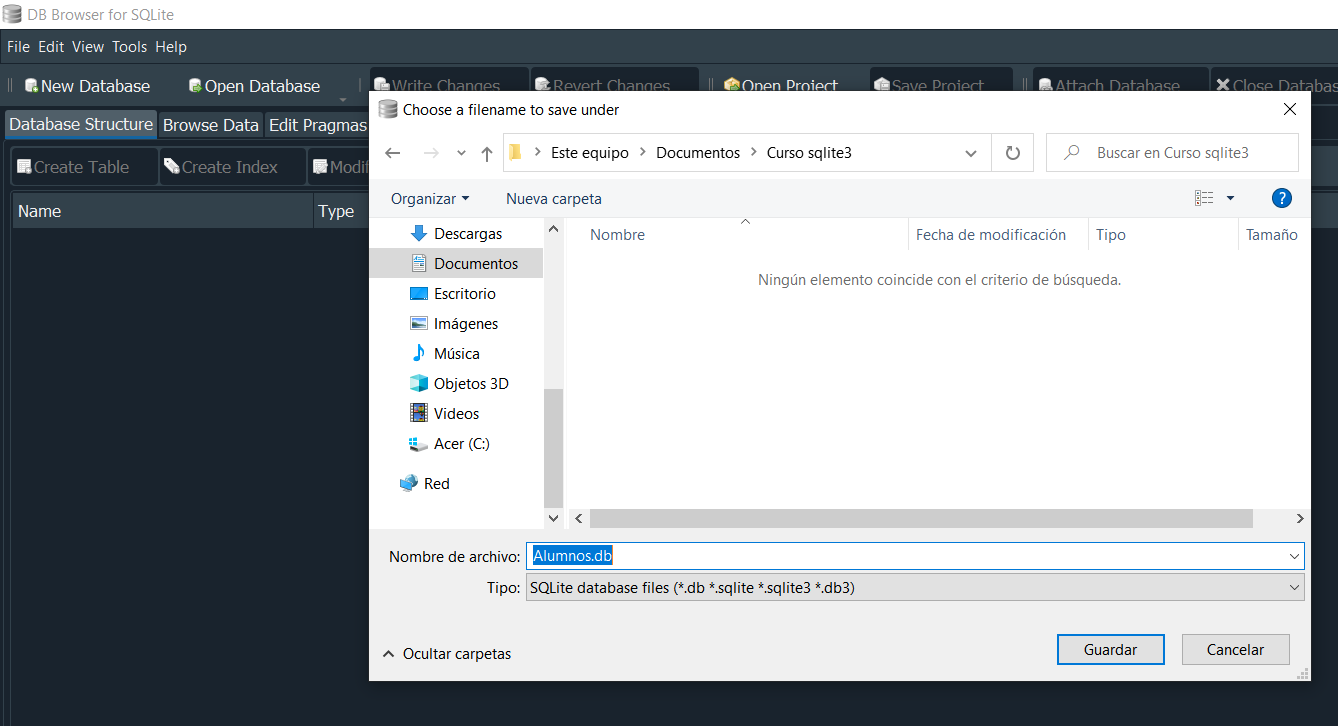
Al darle en Gudardar, automaticamente se nos abrira otra ventana, donde nos pide ingresar un campo de nombre Table, para ello tenemos que primer tener en cuenta el concepto de tabla.
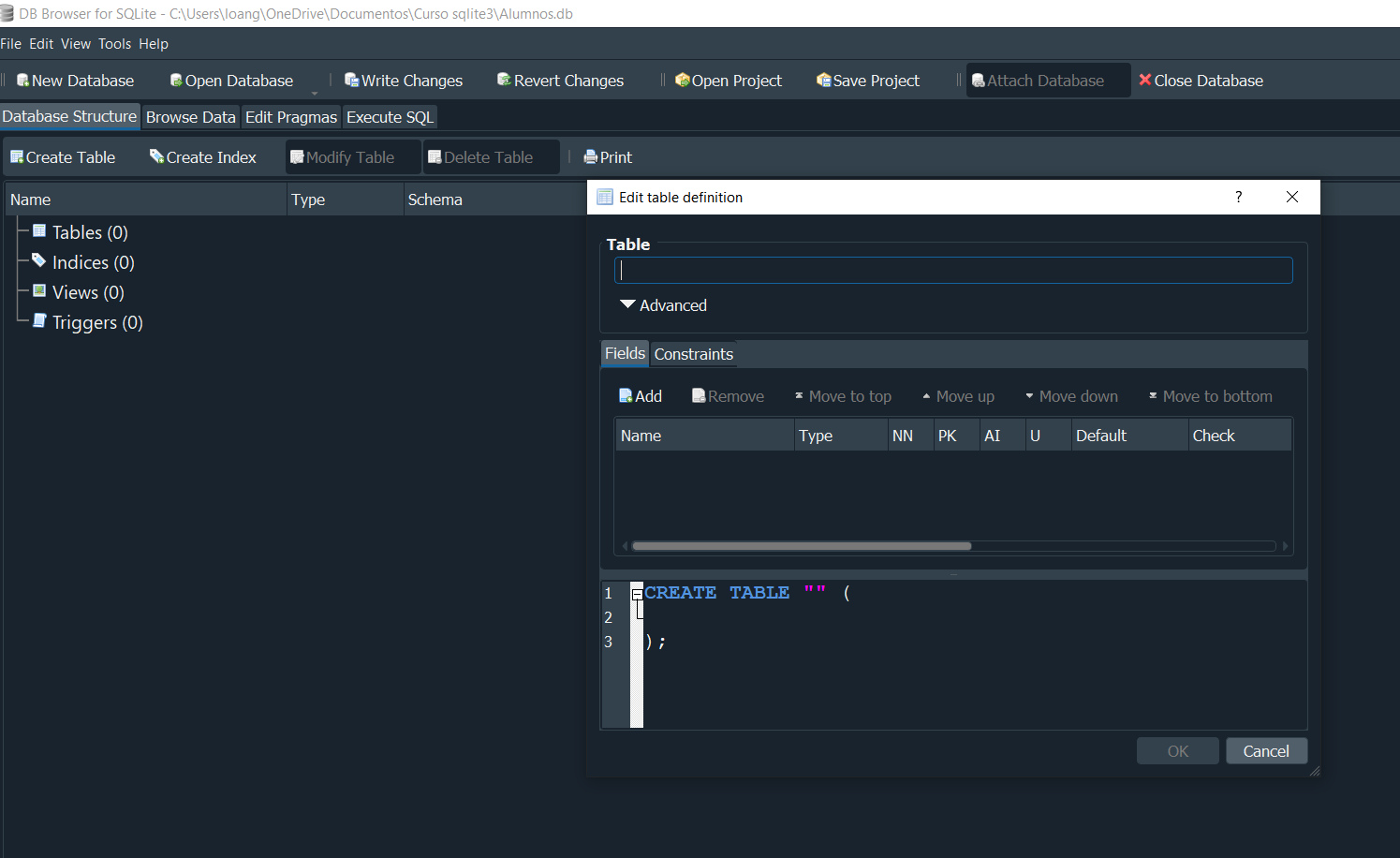
CREAR TABLA - CREATE TABLE #
Es una estructura de datos que se almancenan en filas y columnas y estas obviamente deben de tener un nombre.
Para poder crearlas debemos ejecutar la siguente consulta:
CREATE TABLE "Alumnos" (
);
CAMPOS #
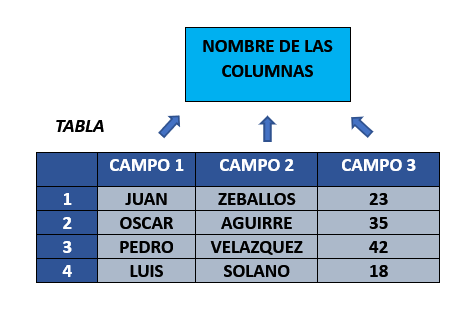
Las tablas a su vez tienen campos, los cuales corresponden a los nombres de las columnas.
REGISTROS #
Ademas de contener campos, tambien contienen registros que vendrian a ser cada una de las filas de las tablas.
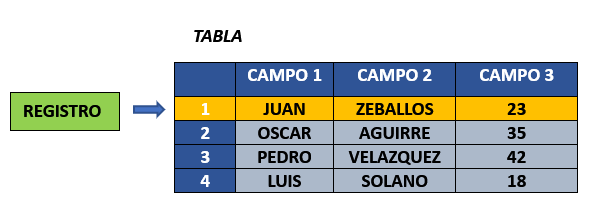
VALOR DE CAMPO #
Vendria a ser cada uno de los valores de la interseccion entre los campos y los registros.
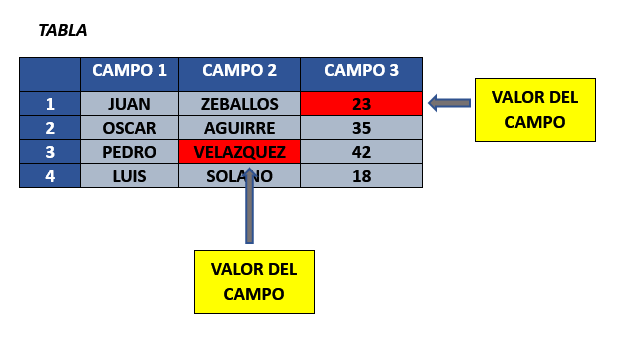
COLUMNAS #
Anteriormente realizamos la creación de una tabla, pero esta no nos serviria sin antes crear los campos o nombres de las columnas, para ello debemos crear los campos que necesitemos segun el tipo de dato que sera almacenado.
Si lo hacemos de manera grafica debemos seleccionar la opcion Add y en Name le indicaremos el nombre que tendra nuestro campo, seguidamente en Type debemos indicar el tipo de dato el cual sera almacenado.
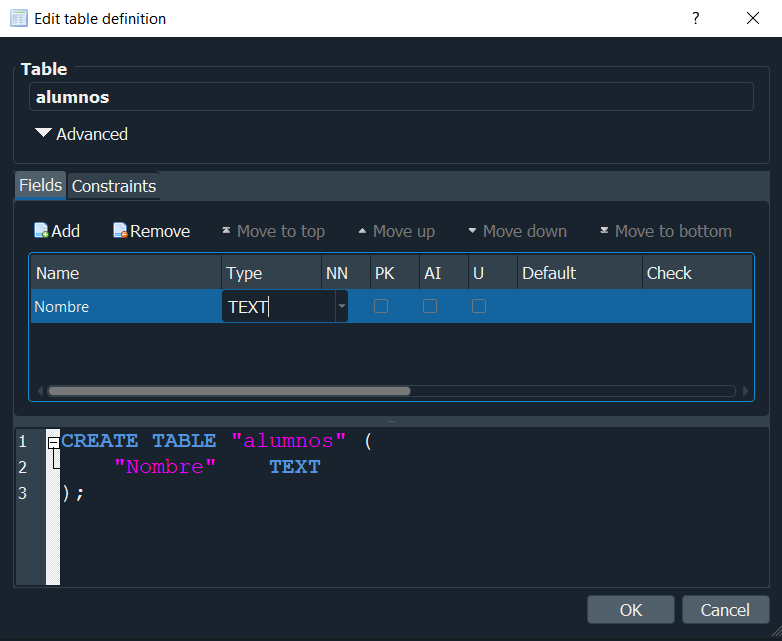
En sqlite existen 5 tipos de datos que podemos usar, estos se corresponden a:
INTEGER:Almacenan valores de tipos de datos enteros.TEXT:Almancenan valores de cadenas de texto.BLOB:Almacena datos binarios, como fotos, videos entre otros.REAL:Almacena numeros flotantes o valores con,.NUMERIC:Almacena numeros que necesitan un calculo matematico preciso, no tienen limites a diferencia que real.
En base a lo previamente mencionado crearemos 3 campos en nuestra tabla, que correspondera a el Nombre , Apellido y la edad. Haciendolo de manera grafica con el gestor solo tendriamos que agregar mas campos con add y si nos percatamos en la parte de abajo se nos muestra el codigo que deberiamos ejecutar si queremos ejecutar para hacer el mismo proceso mediante una consulta.
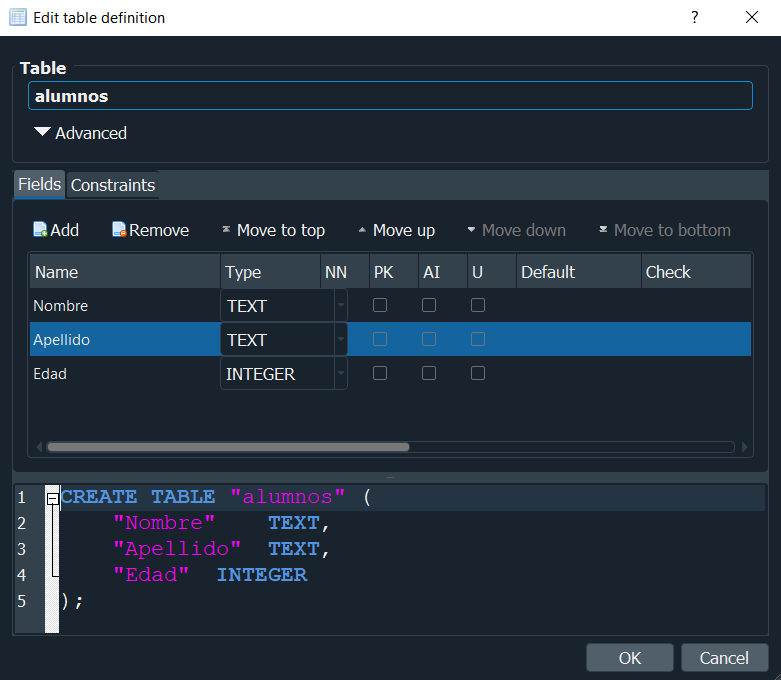
Con esto ya tendriamos una base de datos creada con nuestra tabla Alumnos, lo siguiente seria insertar registros en nuestra tabla, ya que por el momento esta se encuentra vacia.
INSERTAR VALORES EN TABLA - INSERT INTO #
Para poder insertar valores nos vamos al apartado de Execute SQL. Una vez ahi para añadir valores dentro de nuestra tabla debemos hacer uso de la palabra reservada INSERT INTO, y especificar el nombre de la tabla en este caso Alumnos , abrimos () y digitamos el nombre de los campos , seguidamente usamos la palabra VALUES y de igual manera en () los valores que queremos insertar.
Ahora para correr nuestra query solo debemos darle click a el boton run o presionar la combinacion de teclas CTRL + ENTER
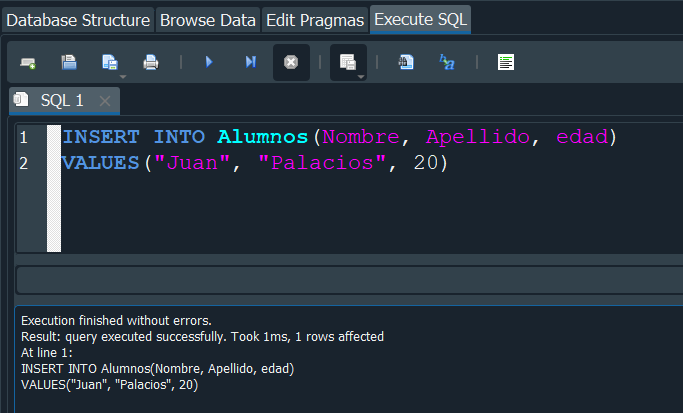
En la parte de abajo se nos mostrara un mensaje comunicandonos que la consulta se ejecuto sin errores.
CONSULTAS O QUERYS #
Una consulta o query son las solicitudes o operaciones que realizamos a una base de datos. Basicamente las consultas se usan para realizar la operaciones basicas CRUD, las cuales son el acronimo de:

INSTRUCCION SELECT #
La consulta SELECT, nos devuelve un conjunto de resultados de registros de una o varias tablas. Podemos seleccionar todos los campos haciendo uso de *
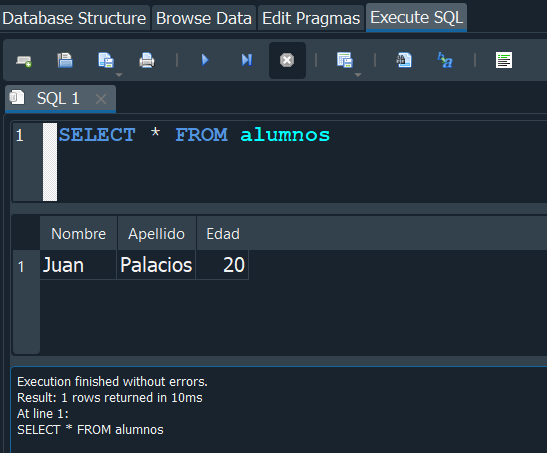
Tambien podemos seleccionar un campo o mas especificos separandolos por comas ,.
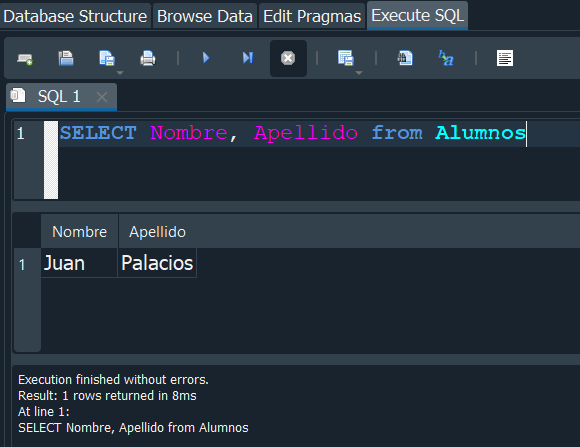
Como resultado nos arroja una tabla nueva con los registros que filtramos.
MODIFICAR TABLA - ALTER TABLE #
Esta instrucción nos permite modificar la estructura existente de una tabla de nuestra base de datos, en otras palabras a que despues de haberla creado podemos hacer modificaciones en ella como cambiarle el nombre, agregar, renombrar o quitar columnas y cambiar el tipo de datos.
RENOMBRAR TABLA #
Si queremos renombrar el nombre de nuestra tabla, debemos usar la instrucción ALTER TABLE mas el nombre de la tabla actual y seguidamente RENAME TO mas el nombre al cual deseamos cambiar.
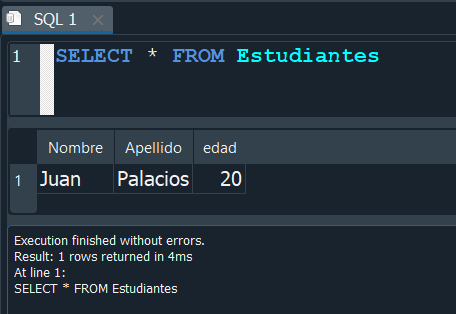
En este caso aplicaremos el proceso a nuestra tabla Alumnos para renombrarla como Estudiantes.
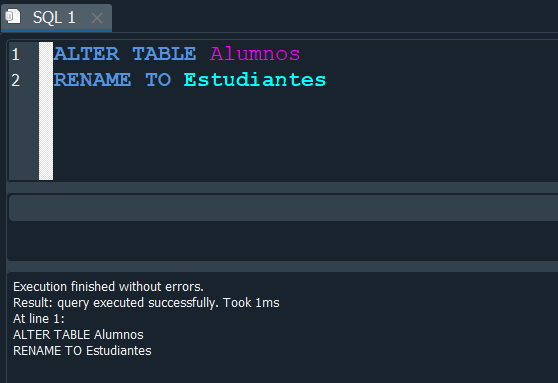
y de esta manera vemos que se efectua correctamente y ahora si queremos seleccionar los datos de nuestra tabla, debemos hacerlos con el nuevo nombre que ahora corresponde a Estudiantes.
RENOMBRAR COLUMNA #
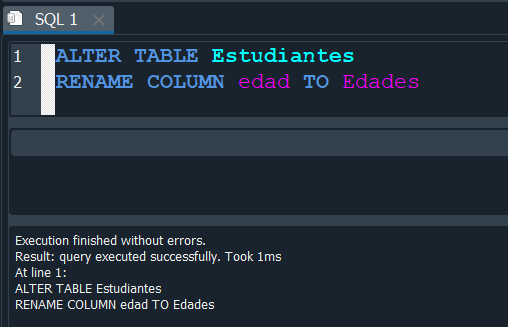
De la misma manera que renombramos la tabla, tambien podemos hacer el proceso similar para renombrar una columna, para ello debemos ejecutar igualmente la sentencia ALTER TABLE mas la tabla que contenga a la columna, despues RENAME COLUMN mas el nombre actual de la columna y finalmente con TO le especificamos el nombre al cual lo vamos a cambiar.
Vamos a verlo de manera practica aplicandolo a la columna edad de nuestra tabla Estudiantes y la renombraremos como Edades.
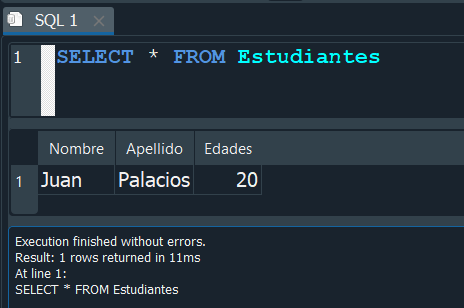
Ahora volvemos a seleccionar la consulta y vemos que renombramos la columna exitosamente.
AGREGAR COLUMNA #
Ahora supongamos queremos agregar una nueva columna a nuestra tabla Estudiantes que corresponda con el nombre de Profesion, pues esto lo hariamos de manera similiar usando de nueva cuenta ALTER TABLE mas el nombre de nuestra tabla, despues usaremos la palabra reservad ADD y seguidamente el nombre que tendra nuestra columna en conjunto con su tipo de dato.
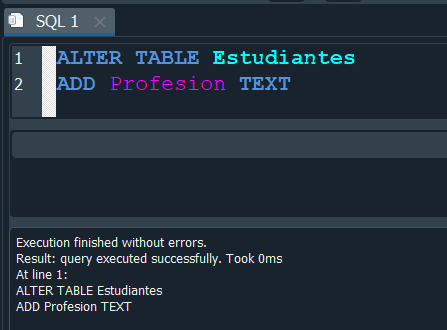
Si visualizamos nuevamente nuestra tabla Estudiantes observamos que ahora se añadio la columna Profesion.
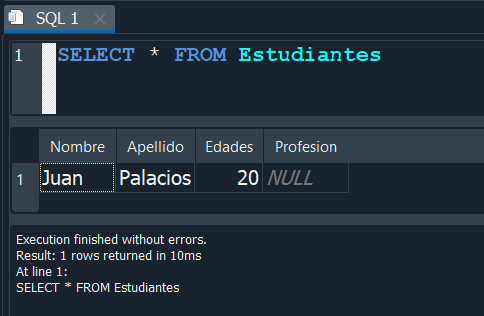
ELIMINAR COLUMNA #
Para pode eliminar una columna, si supongamos esta no corresponde o cometimos un error al crearla es bastante similar a la creacion de una, solo que en este caso debemos nuevamente usar la sentencia ALTER TABLE con el nombre de la tabla y despues DROP COLUMN mas el nombre del campo a eliminar.
Vamos a aplicarlo para borrar el campo previamente creado que fue Profesion, ejecutamos la consulta de manera exitosa.
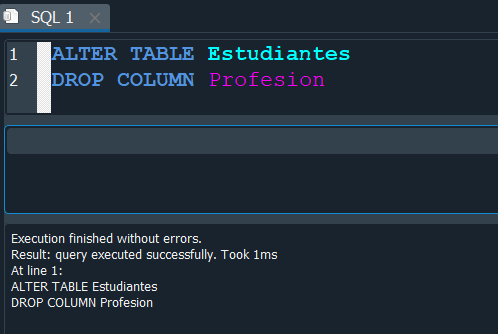
Si nuevamente vemos nuestra tabla Estudiantes, ahora el campo profesion fue eliminado.
INSTRUCCION DROP #
Esta sentencia probablemente solo la utilizaremos cuando estemos en la fase de construcción de nuestra base de datos, ya que en esta etapa haciendo los cambios pertinentes hasta que este lista, de otro modo si la ejecutariamos en produccion los resultados serian desastrozos y posiblemente irreparables si no contamos con una copia de seguridad.
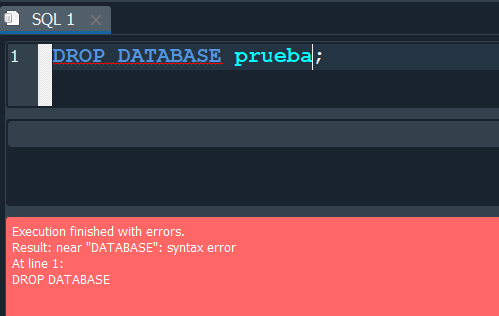
ELIMINAR BASE DE DATOS - DROP DATABASE #
Para eliminar una base de datos solo debemos de ejecutar DROP DATABASE y seguidamente el nombre de la base de datos, sin embargo esta instrucción no se puede ejecutar en sqlite3 asi que tenemos que hacerlo manualmente, pero otros gestores si permiten esta opción asi es que es bueno saberlo.
ELIMINAR TABLA - DROP TABLE #
Para poder eliminar una tabla debemos de ejecutar la instrucción DROP TABLE y seguidamente el nombre de la tabla a eliminar.
Vamos a crearnos para el proceso una tabla de nombre prueba, que contenga los campos nombre y edad con datos cualquiera.
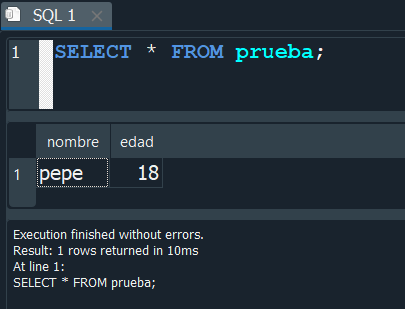
Ahora en esa tabla ejecutaremos la instrucción y vemos que la tabla se elimina.
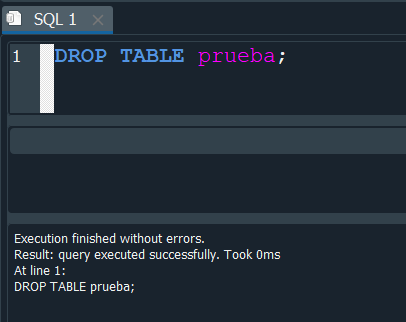
pero aqui hay algo que quisiera agregar, cuando ejecutamos nuevamente el comando este nos devuelve un error en vista que ya no existe la tabla.
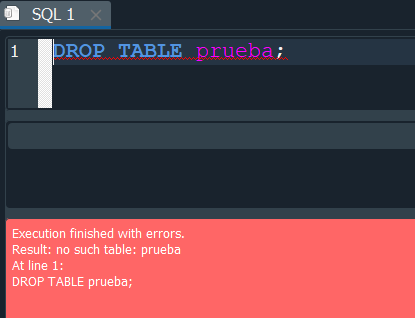
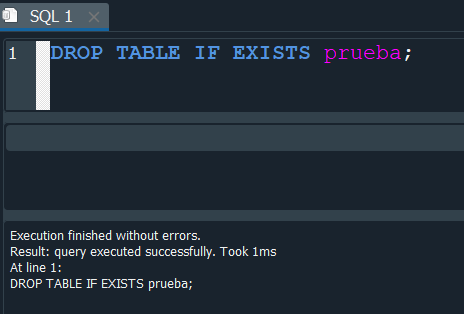
Para poder solucionar eso cuando se realize una creación de tabla o eliminación usar la palabra reservada IF EXISTS y de esa manera comprueba la existencia de la tabla antes de borrarla y en consecuencia evitamos los errores.
IDENTIFICADORES #
Cuando estamos insertando registros, debemos de poder usar un metodo que nos permita diferenciar los registros de tal modo que cada uno de estos sea unico. Aqui es donde comenzamos a usar los identificadores los cuales son de dos tipos: claves primarias y claves foraneas.
CLAVES PRIMARIAS - PRIMARY KEYS #
Cada tabla debe de tener su identificador unico, que no se puede repetir para poder diferencias los registros, esto se conoce como clave primary, la cual no puede ser nula y es autoincrementable.
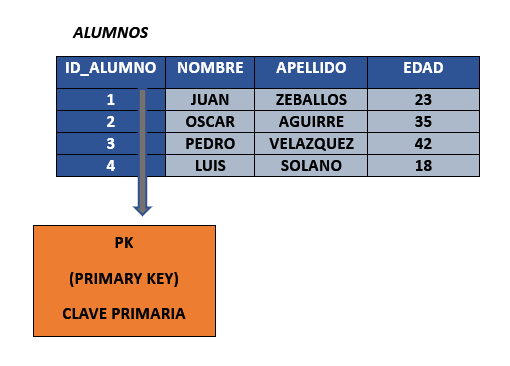
Si queremos definir una clave primaria en nuestra tabla anteriormente creada, primero tendriamos que eliminar todos los registros, de otro modo no podremos hacerlo. Por ello siempre al momento de crear una tabla es necesario definir nuestra clave primaria y evitar problemas.
En nuestro caso vamos a eliminar los registros para seguir trabajando con muestra tabla Àlumnos y esto lo hacemos con otra consulta la cual es DELETE.
INSTRUCCION DELETE #
Para borrar los registros debemos usar la palabra reservada DELETE FROM y a continuación el nombre de la tabla.
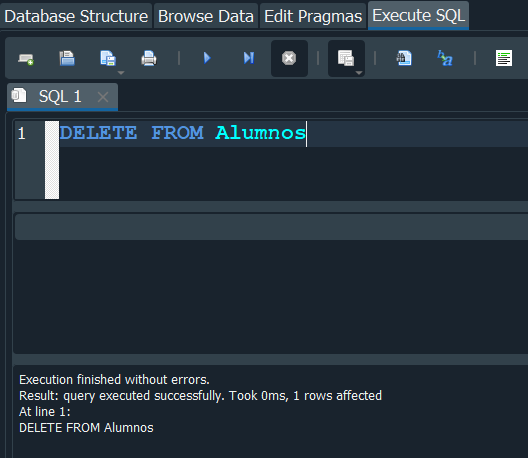
Si queremos hacerlo de manera grafica, nos vamos a la opción Database Structure, buscamos la tabla y le damos en modificar.
Se nos volvera a abrir nuevamente la misma pestaña de cuando creamos la tabla, pero ahora modificaremos los valores y añadiremos un campo id_alumno y seleccionaremos las opciones de PK clave primary - auto-incrementable.
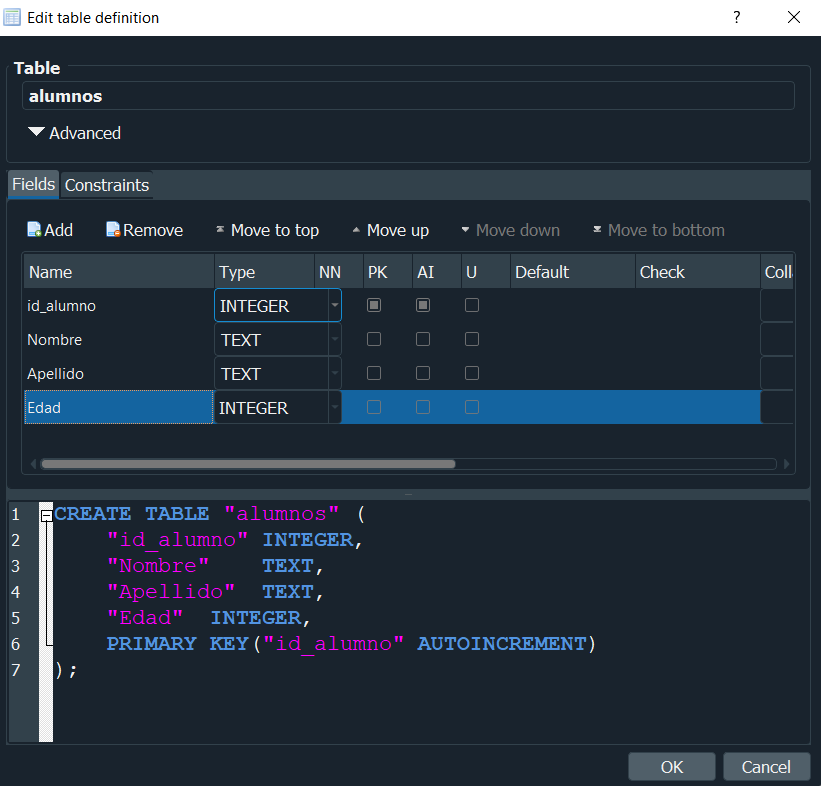
Tambien podriamos hacerlo desde el apartado de Execute Sql insertando la siguiente consulta que nos marca el propio gestor.
Una vez modificada la tabla, probamos a insertar nuevamente varios registros con INSERT INTO que lo vimos previamente.
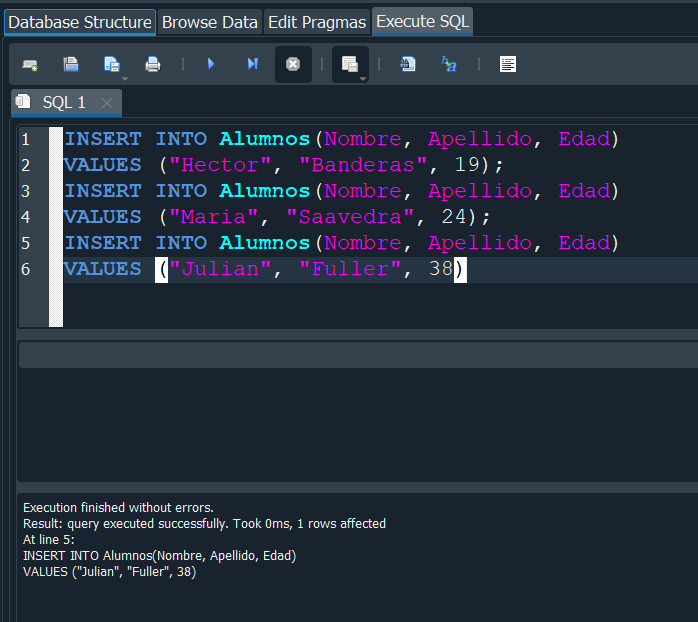
No es necesario que especifiquemos el campo id_alumno, puesto que es auto-incrementable.
Debemos tener en cuenta que si ejecutamos varias consultas, entonces tenemos que separarlas con
;.
Ahora verificamos los registros insetados haciendo uso del SELECT.
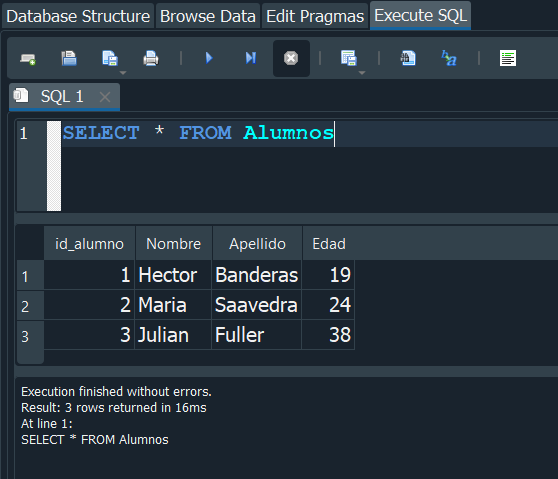
Si vemos esta vez el id_alumno nos muestra el numero de identificador distinto el cual hace que los registros que ahora tenemos sean unicos.
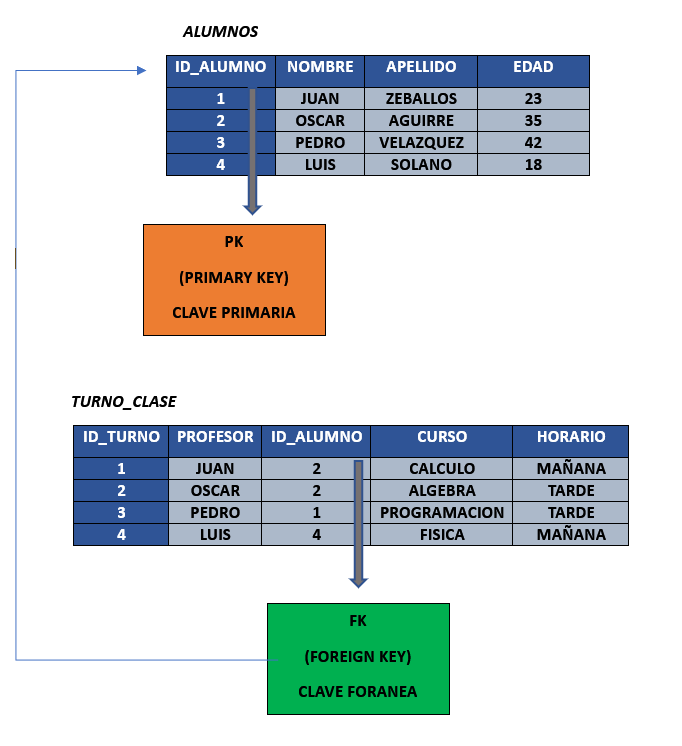
CLAVES FORANEAS - FOREIGN KEYS #
Para entender lo que es una clave foranea, primero vammos a crear una neuva tabla y la llamaremos turno_clase.
Como ya vimos anteriormente cada tabla tiene su clave primaria, pero esta vez vemos que en la tabla turno_clase existe un campo id_alumno que no esta haciendo referencia a una clave primaria ya que esta se repite. Entonces te preguntaras a que hace referencia entonces ese campo?
Pues ese campo se llama clave foranea ya que se utiliza para hacer referencia a una clave primaria de otra tabla, en este caso a la clave de la tabla alumnos.
Ya que la tabla turno_clase necesita hacer referencia a los alumnos mediante el valor unico que tienen correspondiente al id_alumno y con ese identificador podemos tener acceso a toda la información de los alumnos.
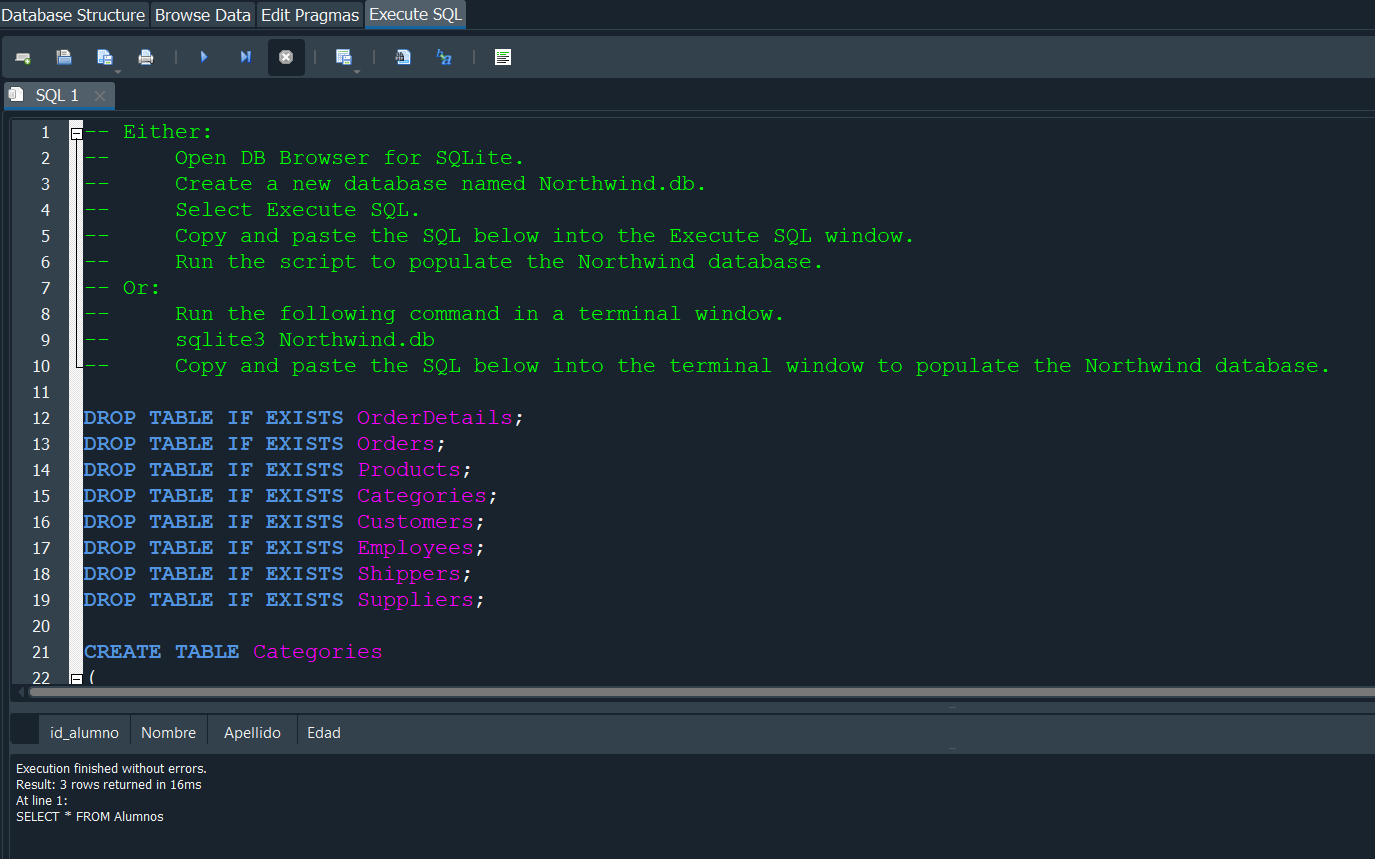
En este punto para poder continuar aprendiendo todas los tipos de consultas que nos falta es necesario que tengamos una Base de Datos de mayor escala y asi entender todo de manera mas clara, para ello vamos a descargarnos una de las tipicas bases de datos que se usan a la hora de aprender Sql. En este caso vamos a utilizar la base de datos de Northwind.db del siguiente enlace:
Una vez vayamos a este enlace lo unico que tenemos que hacer es copiar toda la consulta entera y pegarla en el apartado de Execute SQL.
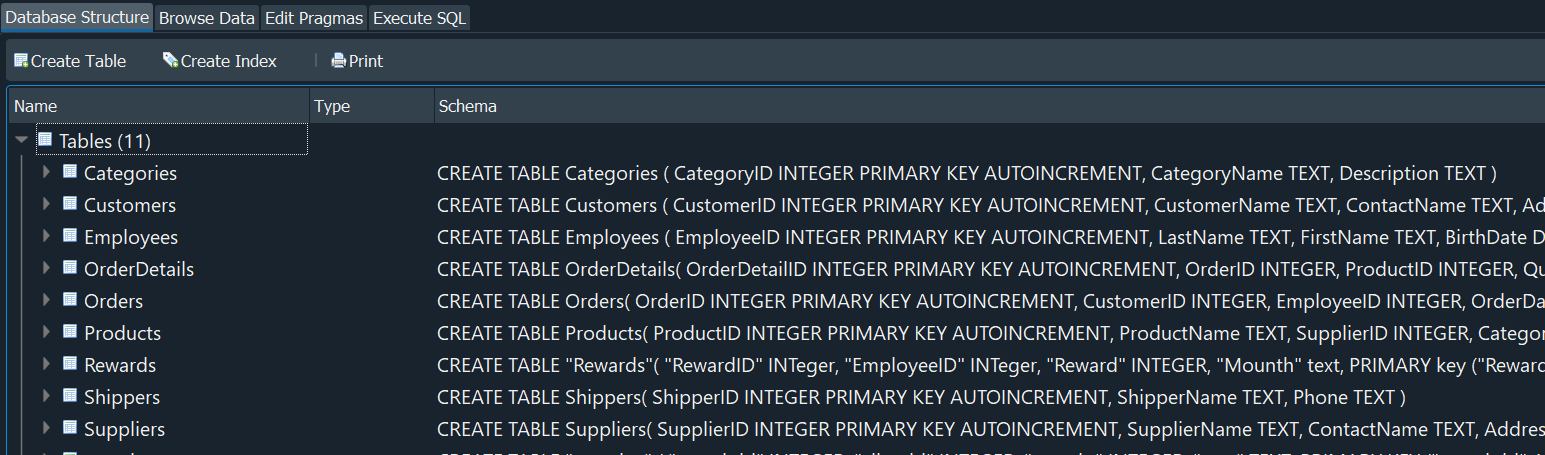
Si ahora nos dirigimos al apartado de Database Structure podemos visualizar la DB Northwind.db, y ahora estamos listos para continuar.
CLAUSULA AS O ALIAS #
Anteriormente vimos que podiamos seleccionar registro de las tablas usando SELECT, en este caso al ahora trabajar con northwind podemos probar a seleccionar alguna de las tablas como Customers.
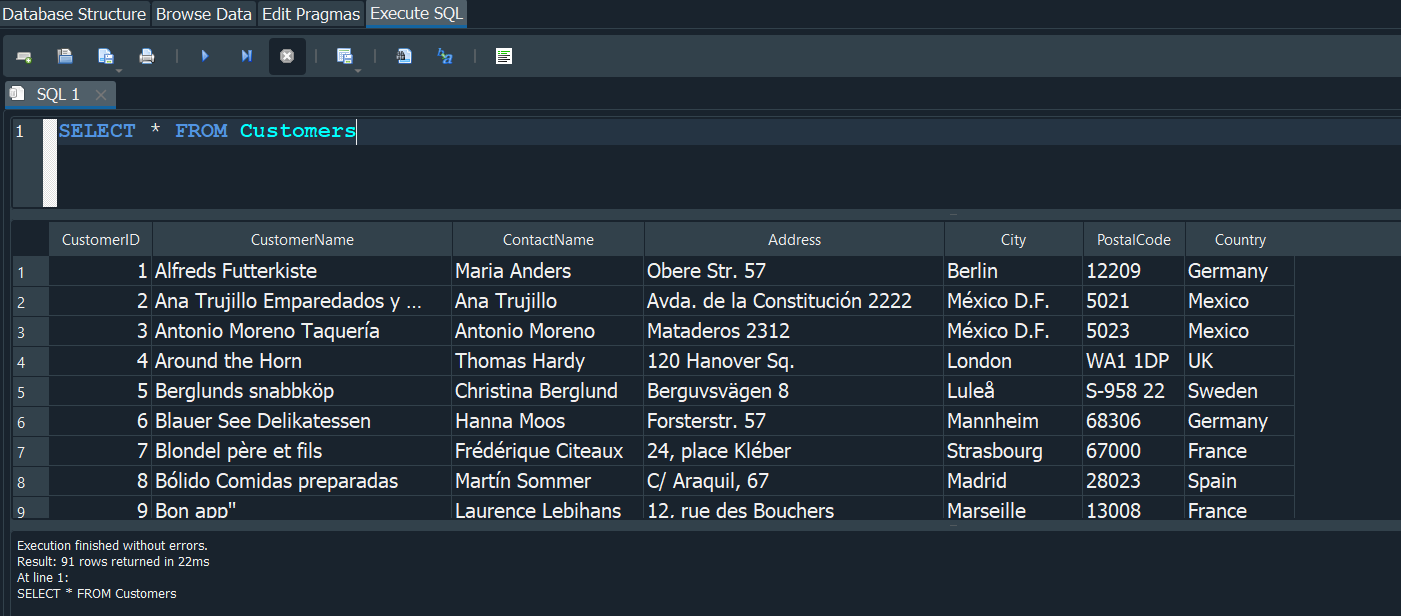
Pero hay ocasiones como esta en las que nos resulte tedioso trabajar con tablas las cuales no creamos previamente nosotros y para poder entenderlas mejor queramos cambiar el nombre de los campos de estas por algo mas descriptivo para nostros, es posible esto?.
Pues la respuesta es si y eso lo hacemos con la palabra reservada AS despues de seleccionar los campos deseados y especificamos el nombre al que queremos renombrar para que se muestren en los registros, no debemos olvidar que con FROM especificamos de que tabla queremos hacer la consulta.
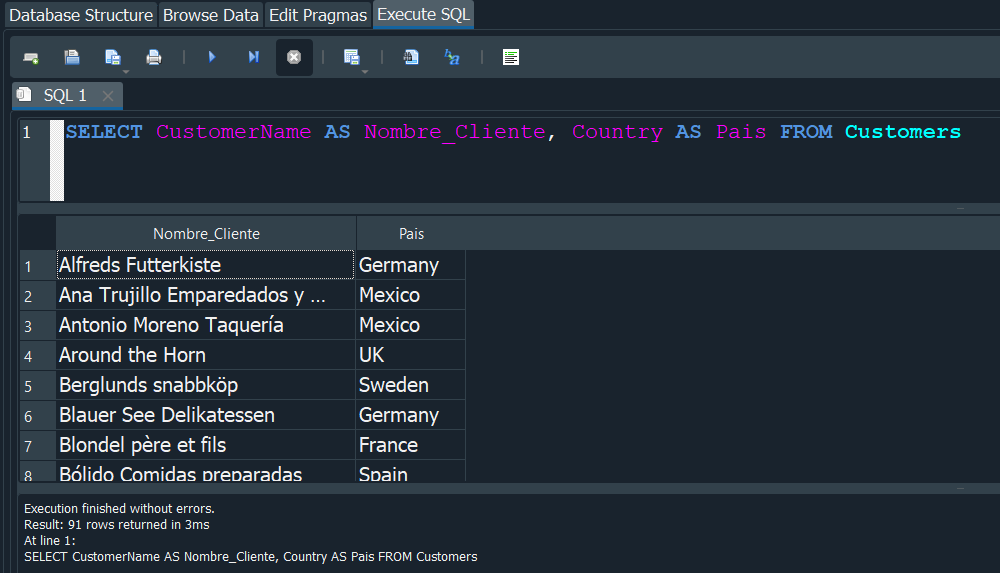
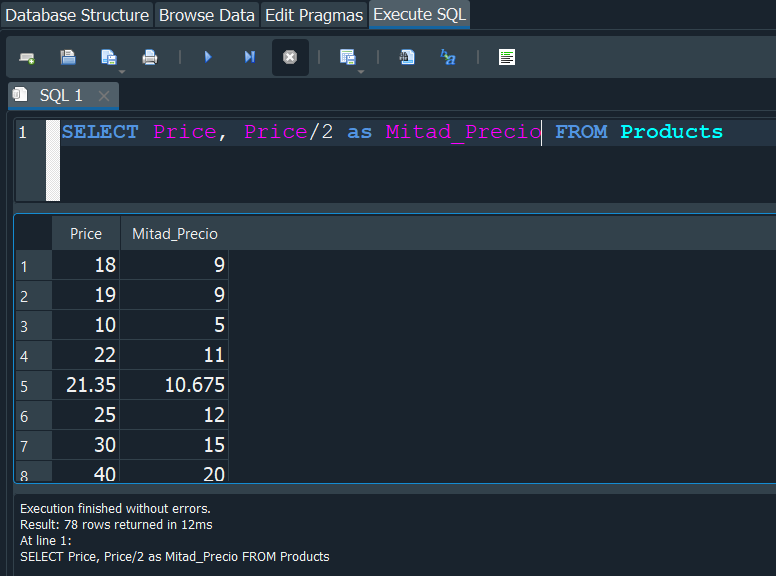
Podriamos usar el mismo concepto para en la tabla Products, supongamos que en nuestra empresa un dia especifico se dan los productos a mitad de precio, nosotros podriamos mostrar el precio normal y tambien otro campo donde nos muestre el precio a la mitad. Ya que al precio ser un valor numerico podemos hacer operaciones como multiplicarlo, dividirlo y entre otras operaciones matematicas comunes como a continuación.
CLAUSULA ORDER BY #
Imaginemos una situación en la que tenemos una tabla, en este caso especifico la tabla Products.
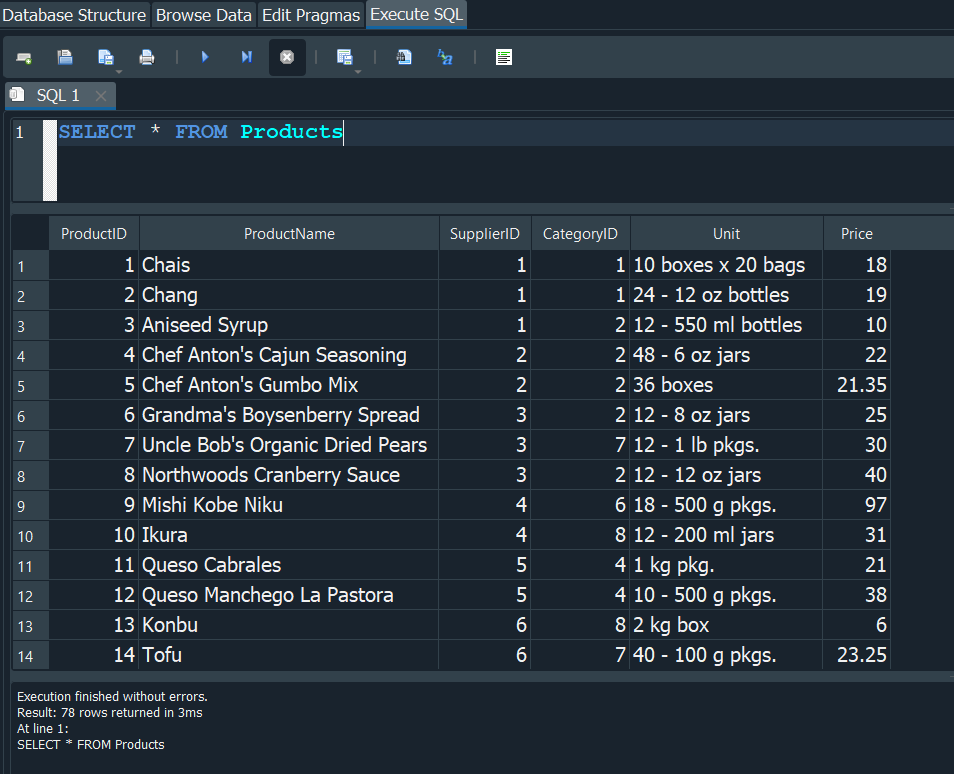
Ahora en la empresa en la que trabajamos, nos piden ordenar la tabla pero no queremos que se ordene por defecto con el product_id, mas bien queremos ordenarlo por el precio.Pues en este caso utilizariamos ORDER BY y seguidamente el campo por el cual queremos ordenarla.
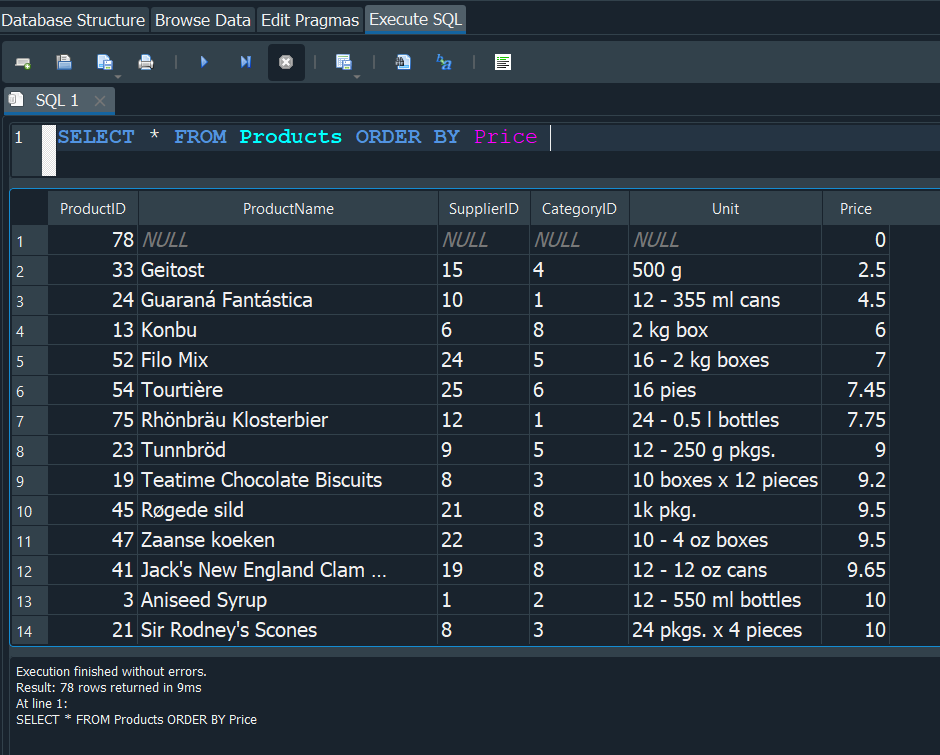
De este modo lo que haria la consulta seria ordenar la tabla en base a la columna de los Precios, pero vemos que nos los ordenar de menor a mayor y nosotros queremos que se ordenen los precios de mayor a menor ya que nos importan los prodcutos que cuestan mas.
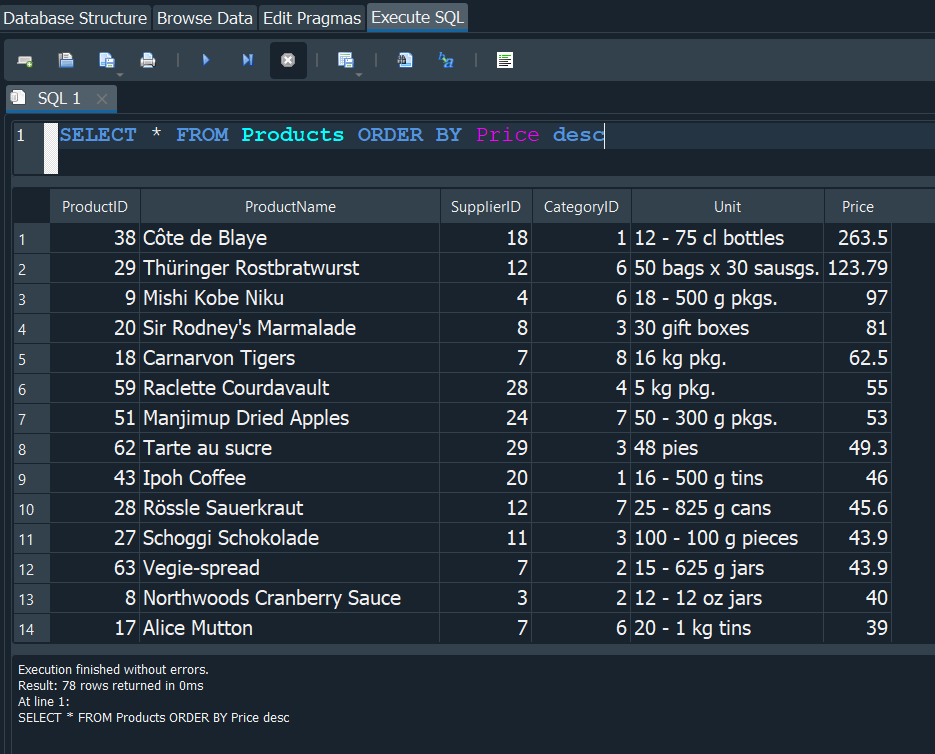
Pues en ese caso usuariamos DESC al final para poder ordenarlo en modo DESCENDENTE y de igual forma podriamos usar tambien ASC que nos lo ordenaria de manera ASCENDENTE
Entonces te preguntaras genial, me ordenar segun el precio ya que es un valor numerico, pero que pasa si en vez de ese campo, lo ordeno por ProductName?. En ese caso tambien nos lo va ordenar pero al ser tipo de dato TEXT lo hara alfabeticamente.
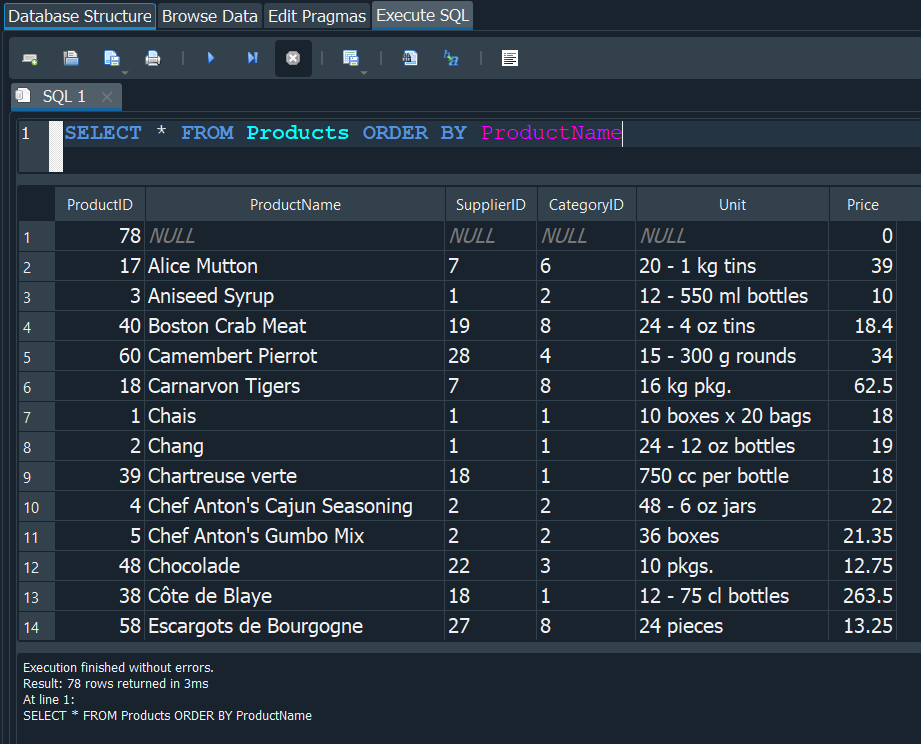
CLAUSULA WHERE #
En SQL la capacidad de usar condicionales es muy importante ya que estas nos permiten encontrar consultas muy especificas. De igual forma que en los demas lenguajes de programación, podemos ejecutar una sentencia en la medida en que la condición se cumpla.
Una de las formas de hacer esto en sql es con el uso de la clausula WHERE.
Si ahora seleccionamos algun campo de una tabla de nuestra base de datos como en este caso de Products, la consulta nos devuelve todos los registros de los campos seleccioandos
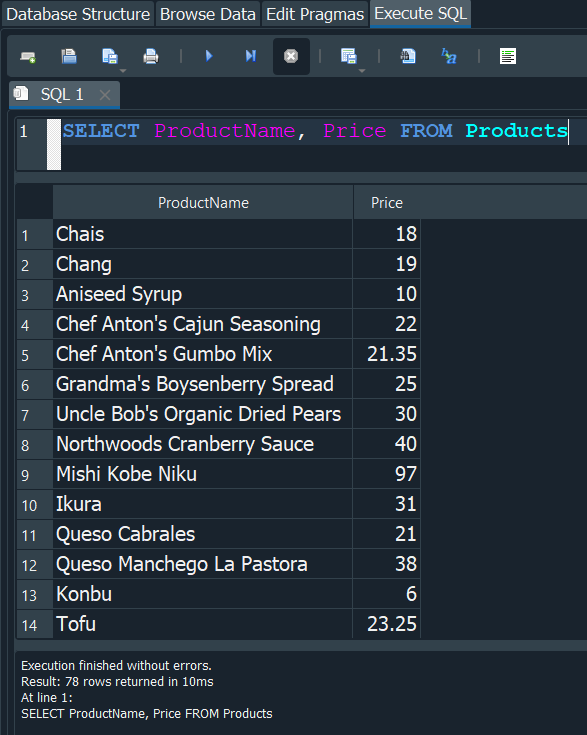
Pero supongamos nosotros solo queremos mostrar uno de ellos, concretamente lo correspondiente al producto Tofu. Pues aqui utilizarimos la clausula WHERE y seguida la condición en este caso queremos que el ProductName sea igual a Tofu.
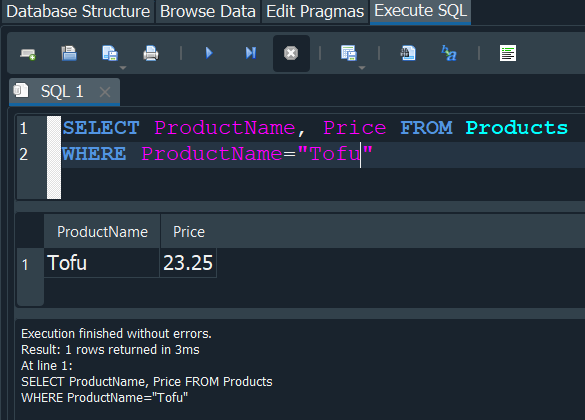
Entonces la consulta nos devolveria los campos, donde solamente el ProductName = Tofu, y de cumplirse la condicion al ser TRUE nos los devuelve, de lo contrario si no existiera nos devolveria FALSE y no se nos mostraria.
Ahora vamos a hacer algo un poquito mas complejo, supongamos que queremos obtener los productos solo si los precios son mayores a 50. En este caso usariamos los operadores de comparación en nuestra codición donde Price > 50.
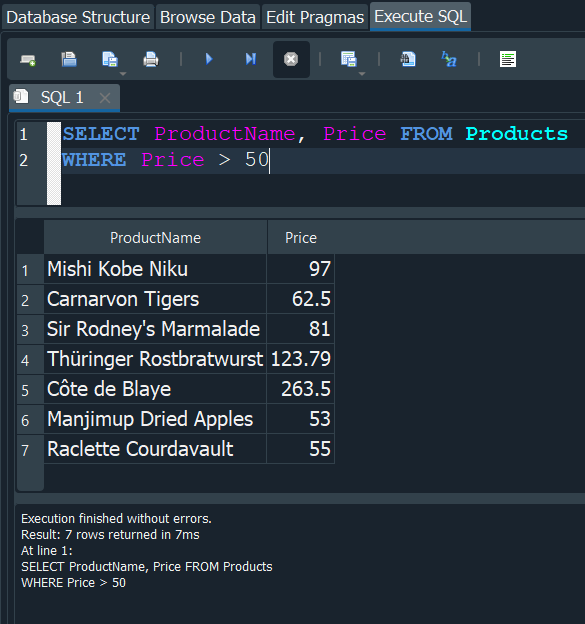
Tambien podriamos usar el WHEREcuando queremos eliminar registros, en este caso vemos que en la tabla Products, existe un producto donde el Precio = 0.
Entonces para eliminarlo usriamos la siguiente consulta usando DELETE y con WHERE, especificariamos la condición de modo tal que se elimine el registro solo si el precio es 0.
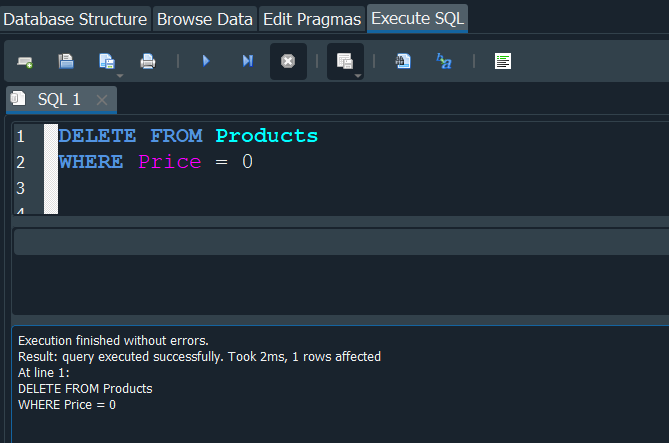
Si ahora volvemos a ejecutar la consulta vemos que efectivamente el registro se elimino.
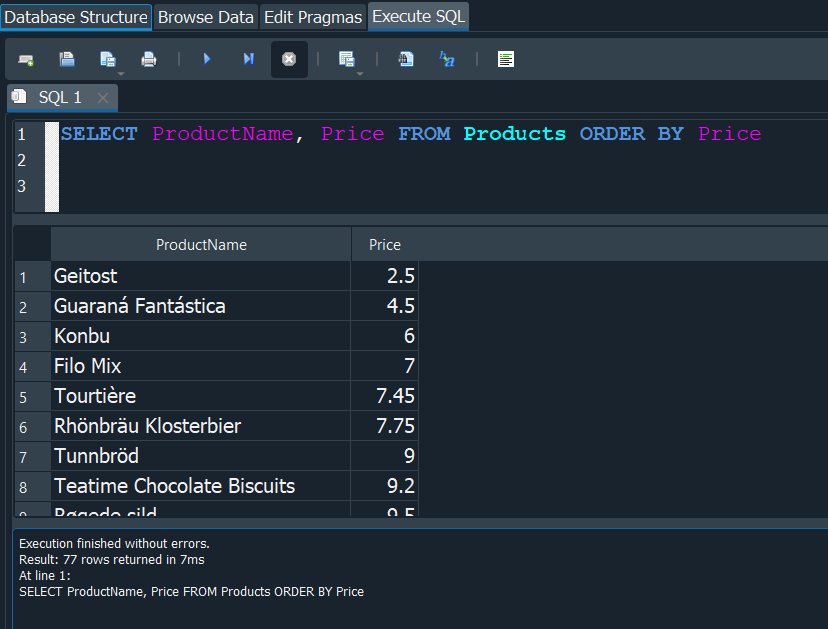
INSTRUCCION UPDATE #
La instrucción UPDATE se utiliza para modificar los datos existentes de una o varias filas.
Usaremos nuestra tabla Estudiantes para modificar la edad de nuestro registro donde el nombre es Juan y asignarle el valor de 30.
Para actualizarlo debemos de ejecutar la instrucción UPDATE mas el nombre de la tabla Estudiantes, despues con SET espeficamos la columna con el valor que deseamos cambiar Edades = 30 y finalmente la condición con WHERE donde especificamos el resgistro especifico en nuestro caso donde el Nombre = "Juan".
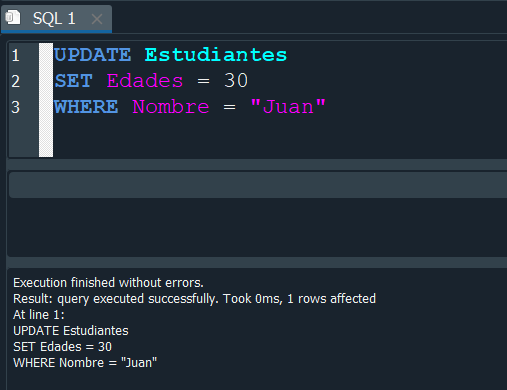
Al ver nuevamente nuestra tabla Estudiantes, ahora en el campo edad nuestro usuario tiene el valor de 30.
OPERADORES EN SQL #
Los operadores son palabras clave en SQL que utilizamos para realizar comparaciones, calculo y combinar condiciones en las consultas y espresiones SQL.
OPERADORES AND Y OR #
Vimos anteriormente que con WHERE podemos aplicar condiciones, pero en muchas ocasiones vamos a querer ejecutar multiples condiciones, y para poder hacerlo tendremos que usar AND o OR.
OPERADOR AND #
Si ya tenemos conocimientos premios en cualquier lenguaje de programación, podemos sobreentender lo que hace AND, que basicamente nos devuelve un resultado de cumplirse ambas condiciones.
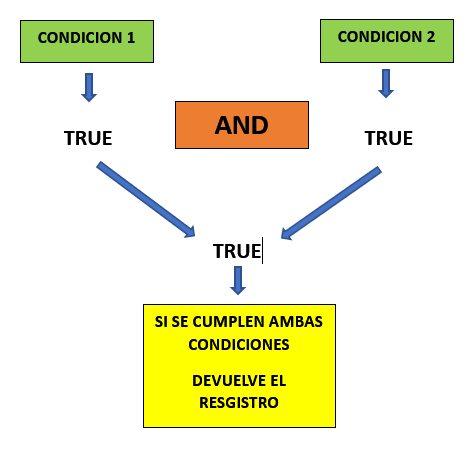
Ahora para el siguiente ejemplo vamos a seleccionar de la tabla Customers solo aquellos donde el pais sea Spain y la ciudad sea Madrid, en caso se cumplan ambas condicones quiero que me devuelva los registros.
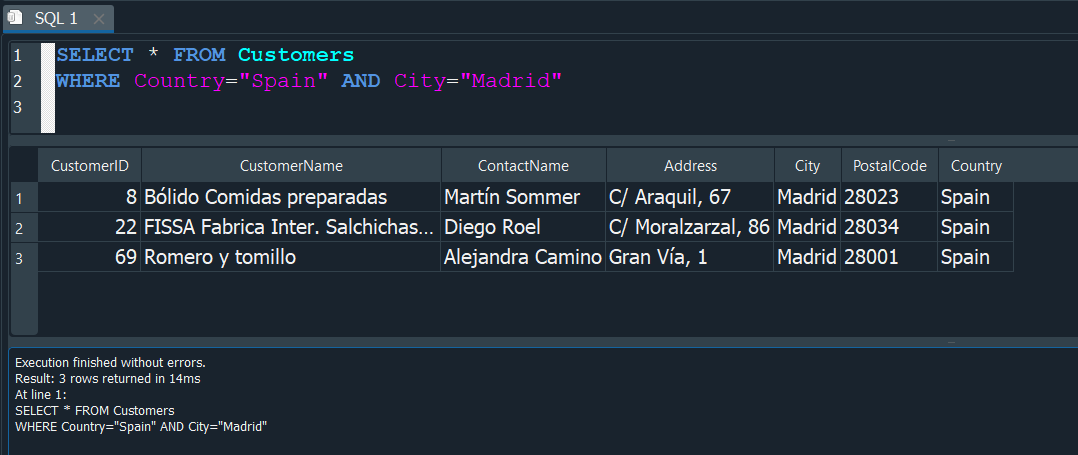
OPERADOR OR #
Al contrario que el and, OR nos devuelve un resultado al cumplirse alguna de las dos condiones, no valida que se cumplan ambas ya que con solo cumplirse una de ellas esta nos devolvera un registro.
Supongamos vamos a hacer una consulta donde, queremos seleccionar a los clientes que son del pais de Argentina o que sean de la cuidad de Barcelona.
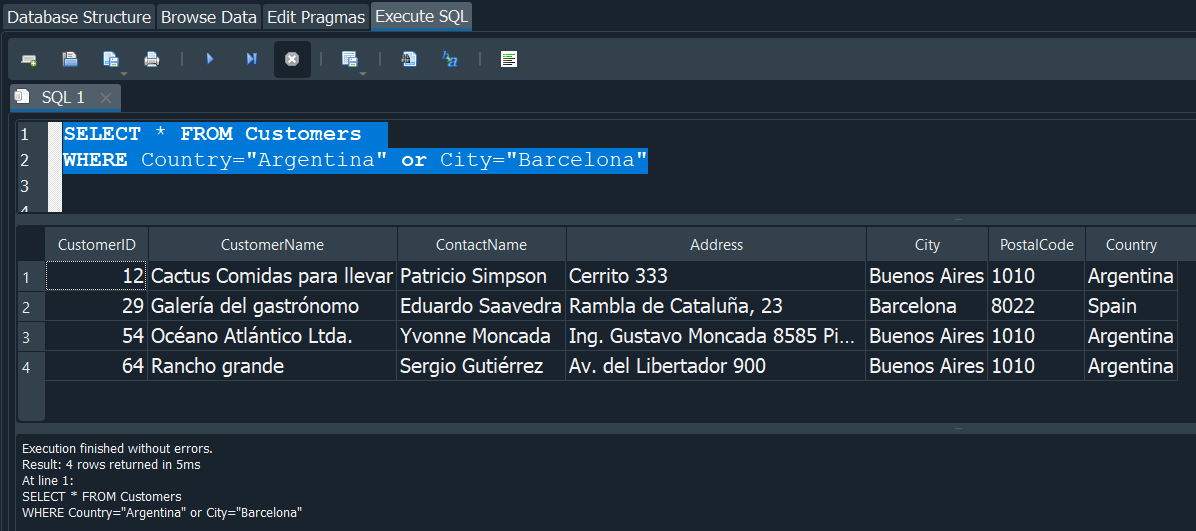
Como resultado tenemos registros donde los clientes son de Argentina y tambien a los clientes que son de la ciudad de Barcelona ya que con OR solo una de las condiones debe cumplirse para que me devuelva los registros.
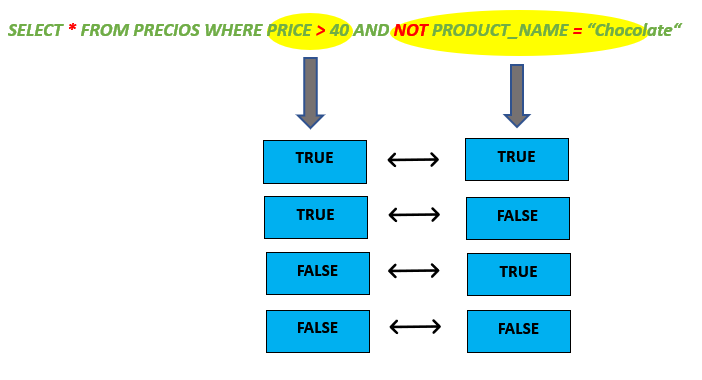
OPERADOR NOT #
Lo que hacemos con NOT es simplemente negar la sentencia que realizamos, de este modo al agregar el NOT el resultado que nos mostrara vendra a ser lo contrario a nuestra condicion en nuestra consulta.
Si quedriamos realizar una consulta donde queremos obtener los precios que sean mayores a 80 de la tabla productos, si ejecutamos la consulta esta nos mostrara exactamente lo que queremos.
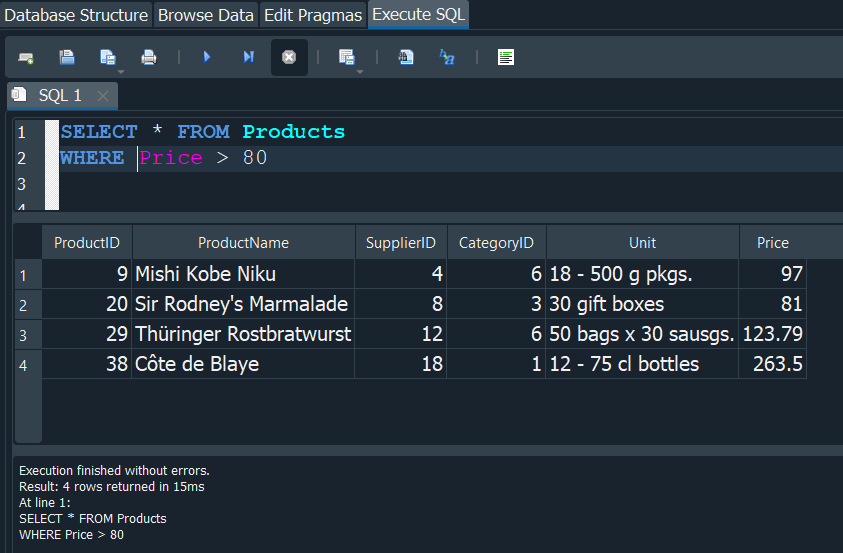
Pero si usamos NOT lo que se hace es negar la consulta y hacer lo contrario, basicamente con NOT le diriamos mediante una consulta que nos seleccione los precios donde NO sean mayores a 80.
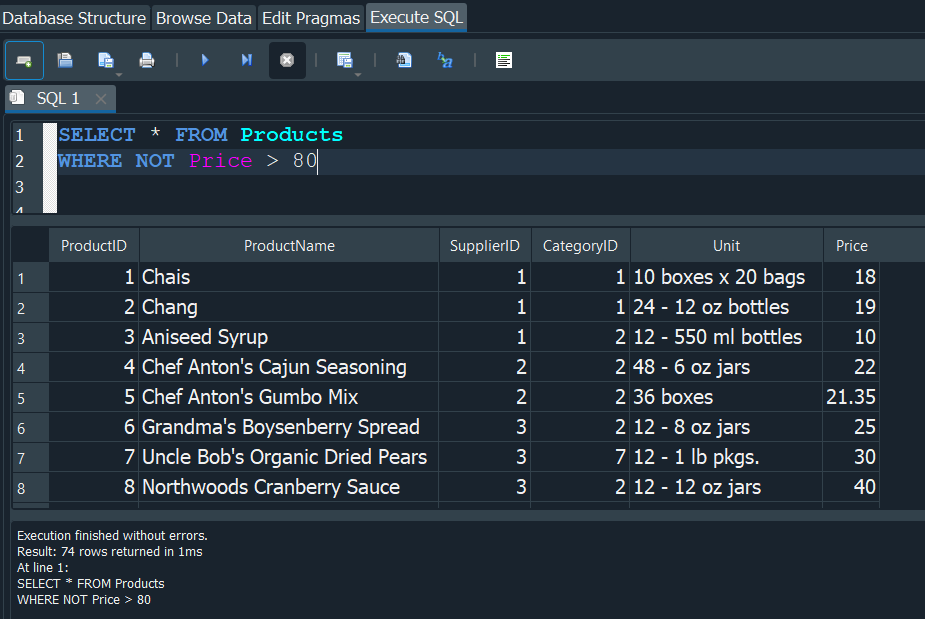
OPERADOR LIMIT #
Cuando queremos limitar el numero de registros que nos arroja una consulta usamos LIMIT, con ello limitamos el numero de registros a cuantos queramos especificando la cantidad total en numeros despues de LIMIT.
Supongamos que ahora queremos ejecutar una consulta que nos muestre de manera ordenada los precios de la tabla de los Products, eso lo hariamos facilmente utilizando ORDER BY . Pero en esta ocasión de esos precios ordenados solo queremos que se nos muestre los 5 primeros registros, pues ahi es donde vamos a utilizar el LIMIT.
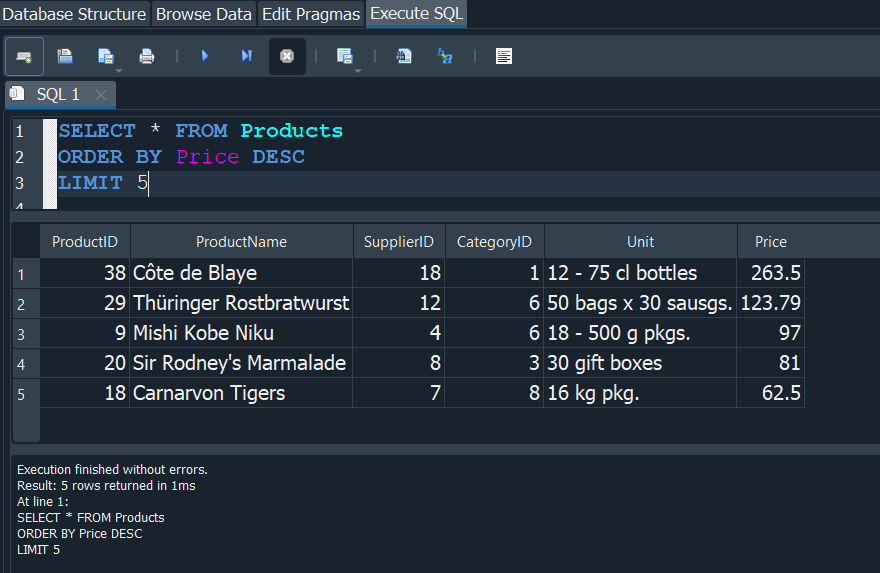
y de esta manera tendriamos el precio de los 5 produtos mas caros.
De la misma manera podriamos modificar la consulta y usar ASC y de esta manera nos mostraria los 5 productos de menor precio.
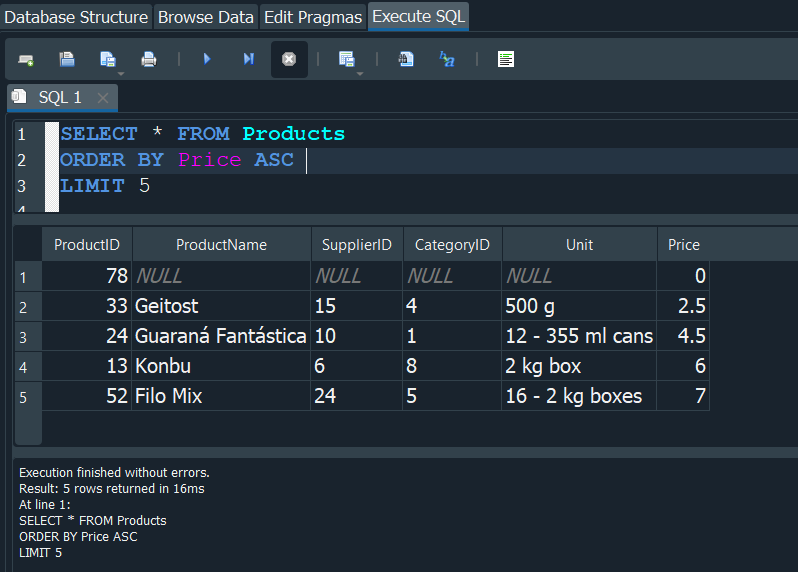
OPERADOR DISTINCT #
Este operador funciona de manera bastante similiar a NOT ya que cuando lo usamos nos ejecuta exactamente lo contrario o distinto a la consulta, pero no es exactamente igual ya que != es un operador de comparación y se ejecuta realizando una comparación con todos los registros hasta validar uno correcto.
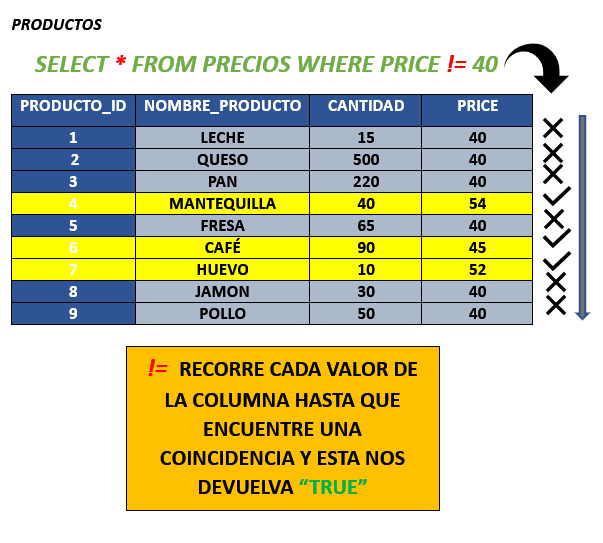
En cambio NOT al ser un operador logico, trabaja haciendo la comparación directamente entre dos valores booleanos.
Si lo aplicamos != a efectos practicos en una consulta esta nos arrojara valores distintos al que especifiquemos, pero ahora ya tenemos en cuenta que no es lo mismo que usar NOT aunque ambos se asemejen mucho.
OPERADOR BETWEEN #
Es un operador de comparación que se utiliza para seleccionar valores en un rango especifico, estos datos pueden ser de tipos numericos, fecha o texto.
Veamos un ejemplo donde vamos a seleccionar un rango de precios de nuestra tabla Products, que iran desde 40 a 50.
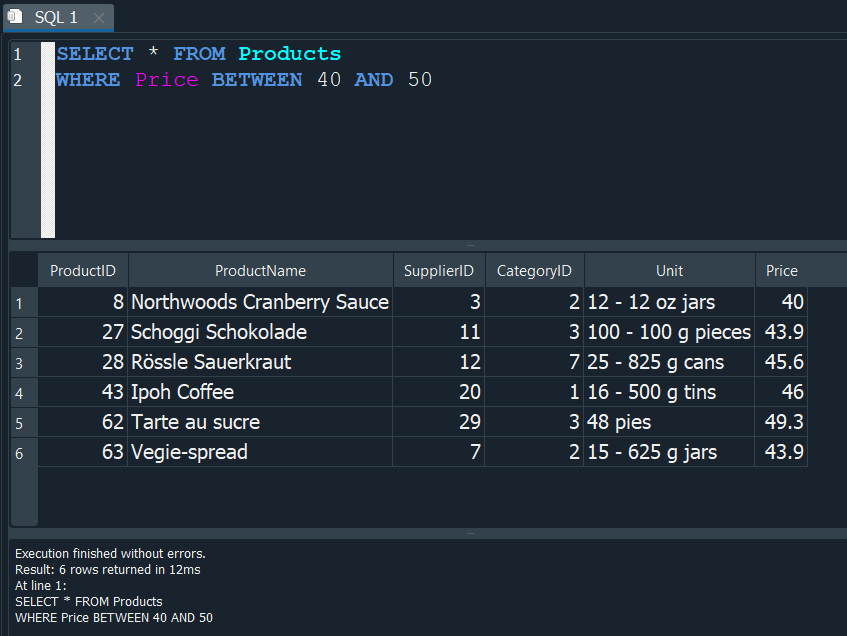
Observamos que la consulta nos arroja unicamente los precios del rango establecido y de esta manera podemos simplificar nuestra consulta usando BETWEEN y de esta manera optimizamos nuestras consultas.
Podemos tambien en vez de especicar un rango basandonos en un dato numerico, usar un dato de tipo fecha.
De esta manera podemos filtrar por un rango de fecha de nacimiento que corresponde a nuestros empleados de nuestra tabla Employees.
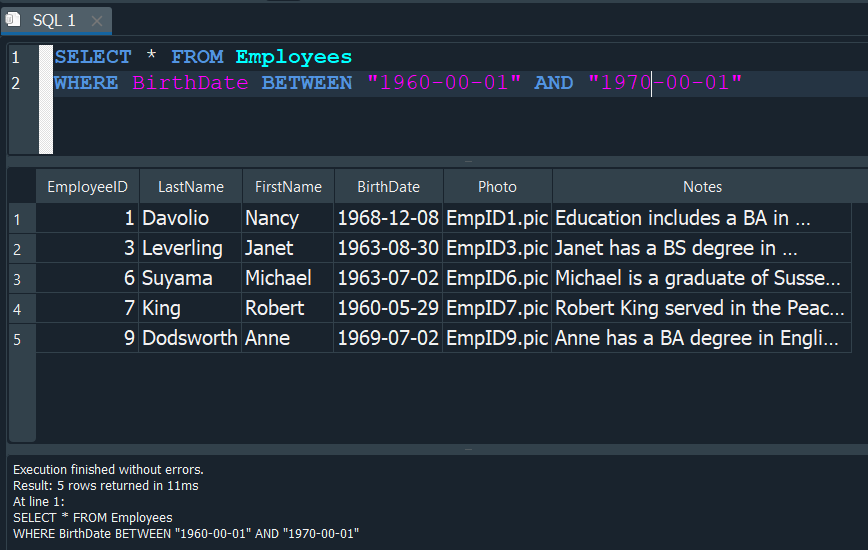
OPERADOR LIKE #
El operador LIKE, lo usamos para hacer un filtro basandonos en patrones de cadena de texto, parecido a una expresión regular pero sin llegar a esa complejidad.
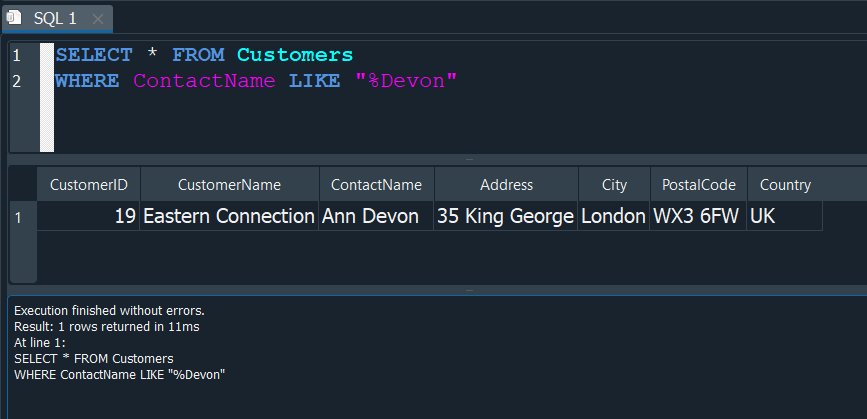
Para poder comprenderlo mejor vamos a usarlo para poder filtrar por cadenas de texto especificas en nuestra tabla de clients Customers.
Realizaremos una consulta donde seleccionemos todos los datos del nombre de contacto ContactName de nuesta tabla Customers , donde con LIKE le especificamos que la cadena de texto especifico por la cual filtraremos, empieze con cualquier valor pero que termine con la palabra “Devon”.
Esto lo hacemos anteponiendo el % y seguidamente el texto por el cual queremos filtrar "%TEXTO".
Del mismo modo si quisieramos que el filtrado sea parecido, pero que esta vez que el filtro empieze por un texto especifico y termine el cualquier cosa, solo debemos poder el %al final TEXTO%.
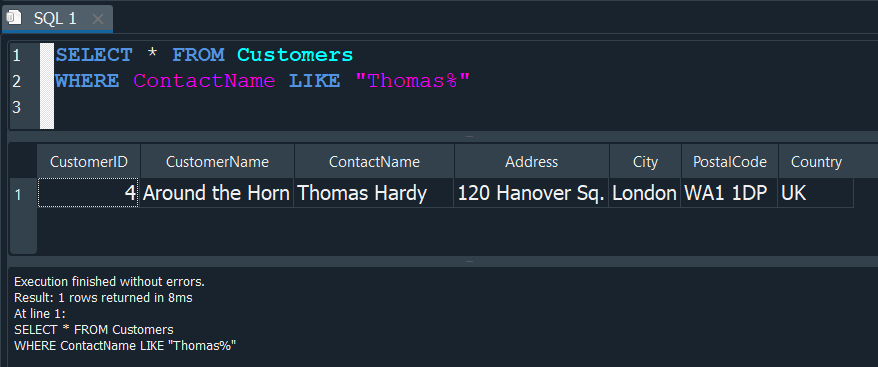
Pero tambien existe una forma de realizar un filtro, donde especifiquemos el texto independientemente comienze o termine, y que nos encuentre un resultado cuando unicamente contenga el texto.
Para ello usamos al inicio y al final % y de esta manera especificamos que no importa si comienze o termine con algo especifico, simplemente nos imprime la consulta si encuentra un match o coincidencia.
De esta forma la consulta nos arroja varias coincidencias donde se cumple la condición.
Ahora tambien podemos hacer otro tipo de filtrado usando LIKE, supongamos queremos realizar una consulta donde buscamos filtrar en nuestra tabla Employees, un nombre el cual comienze con la letra N, termine con la letra Y y ademas el nombre solo tenga cinco caracteres.
En ese caso usaremos _, para especificar el numero total de caracteres desconocidos y en los extremos poner las letras conocidas.
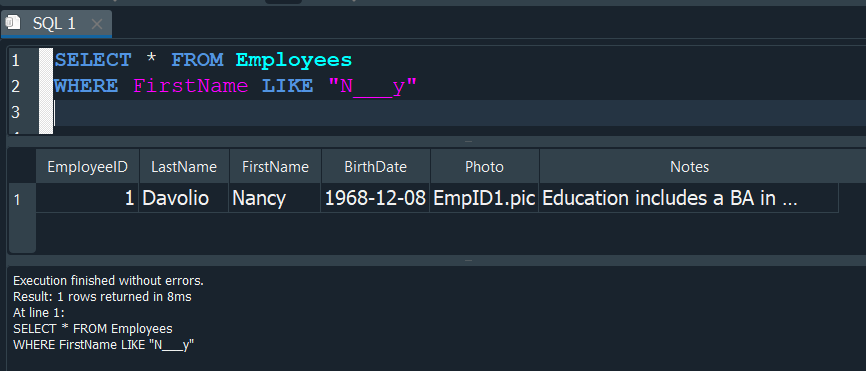
Cada uno de los guiones bajos _, hace referencia a un caracter el cual puede ser cualquiera incluidos espacios.
OPERADOR IS NULL Y IS NOT NULL #
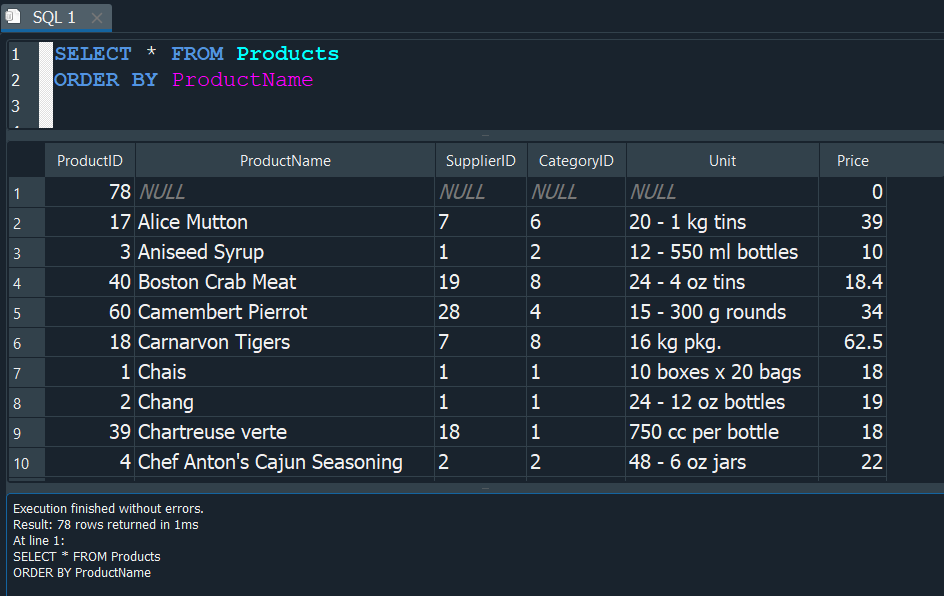
En sql un valor NULL, representa un valor desconocido, cuando insertamos filas en una tabla, sin asignarles un valor, estas automaticamente toman el valor nulo NULL. Este valor al ser especial no podemos compararlo con operadores aritmeticos normales, en su lugar debemos usar los operadores IS o IS NOT.
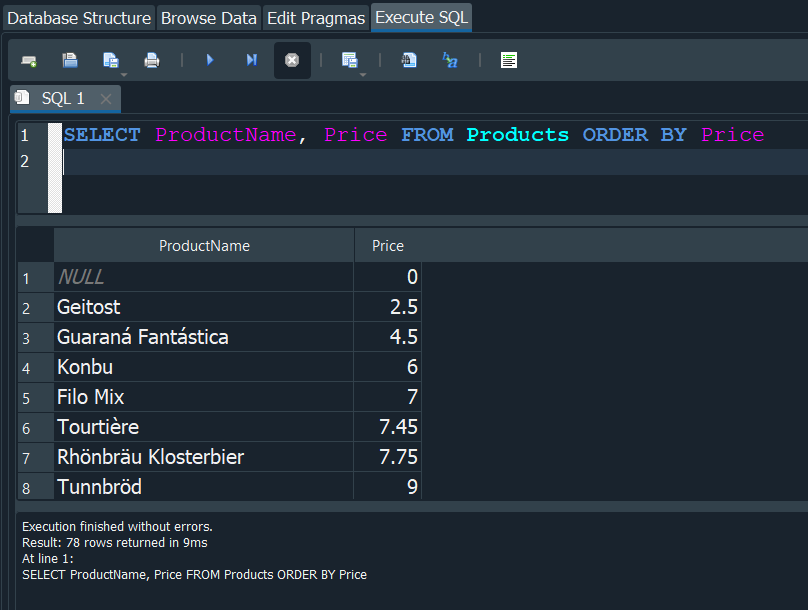
Si seleccionamos todo de la tabla Products y aplicamos un ordenamiento basandonos en ProductName, por defecto esta nos devolvera al inicio los valores NULL, de existir estos.
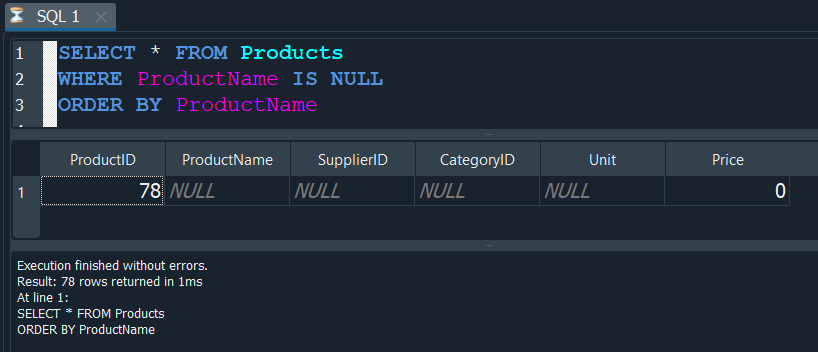
Pero si aplicamos la condición donde vamos a indicarle que nos devuelvan solo los valores NULL. Para ello usamos IS NULL.
Y si al contrario me molestan ver los valores nulos y quiero quitarlos, pues usamos IS NOT NULL.
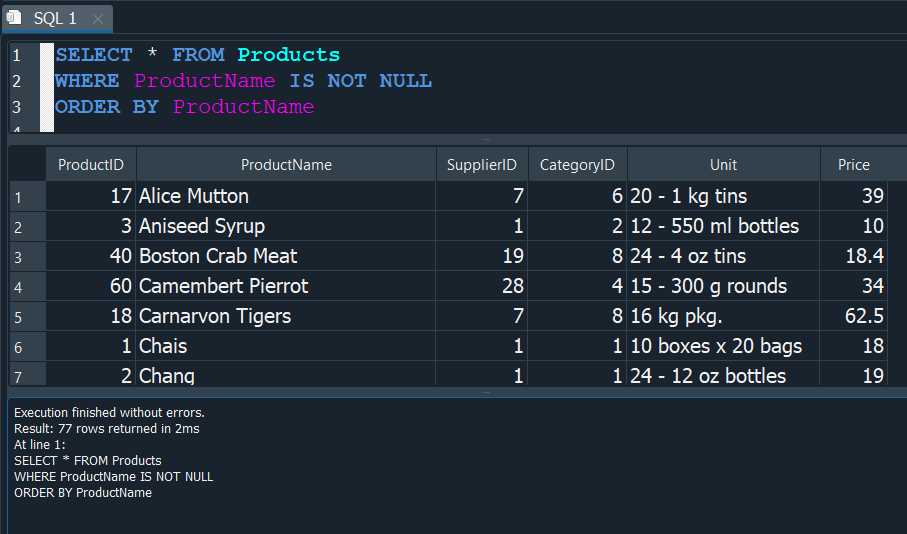
la consulta nos devolvera todos los valores a excepción de los valores NULL.
OPERADOR IN Y NOT IN #
Estos operadores simplifican el uso de usar multiples veces el operador AND y OR al establecer multiples condiciones, ya que opera dentro de una lista de valores similar a una tupla (valor1, valor2, valor3. valor4).
Supongamos queremos listar varios ProductID de la tabla Products, en ese caso deberiamos ejecutar la siguiente consulta.
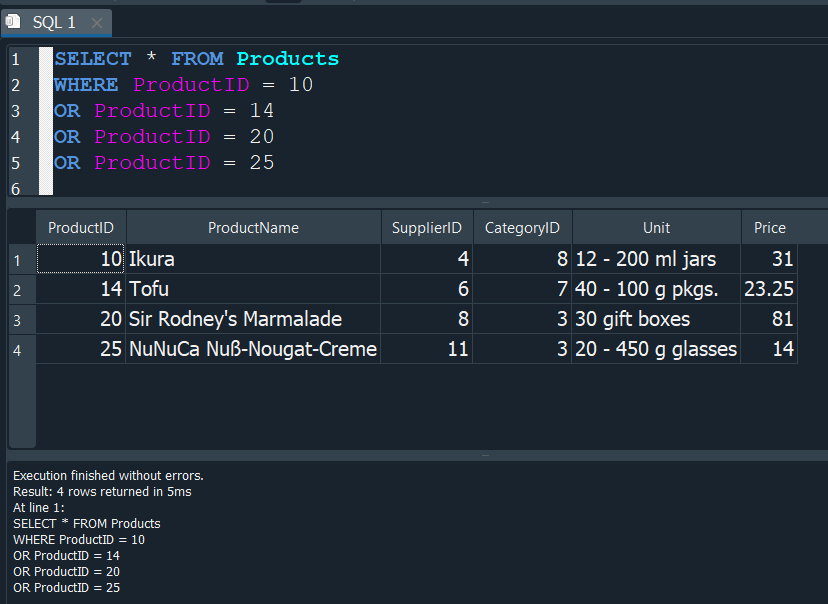
Obtendriamos el resultado deseado, pero escribiriamos muchas lineas de codigo, lo que no seria optimo y mas bien tedioso. Justo en estos casos usamos IN y de esta manera podemos operar sobre un grupo de valores y reducir varias lineas de nuestra consulta, y logrando que sea mas optima.
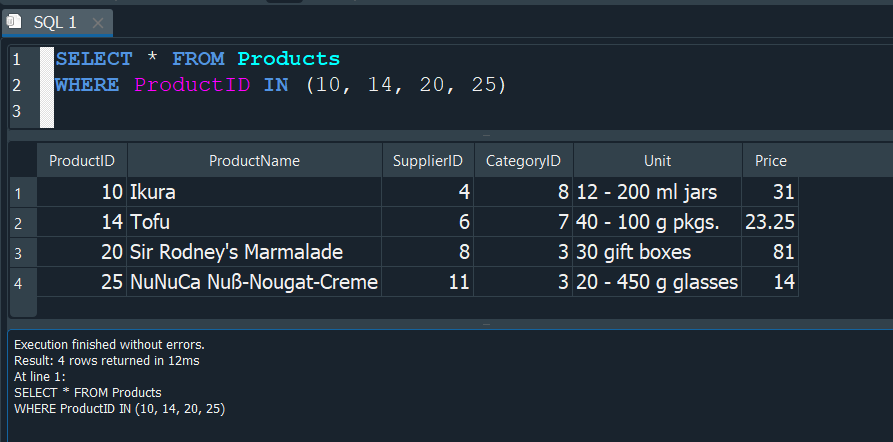
De la misma manera con NOT IN, hacemos exactamente el mismo proceso, solo que esta vez al usar el NOT se ejecutara lo contrario y imprimira los valores que no correspondan.
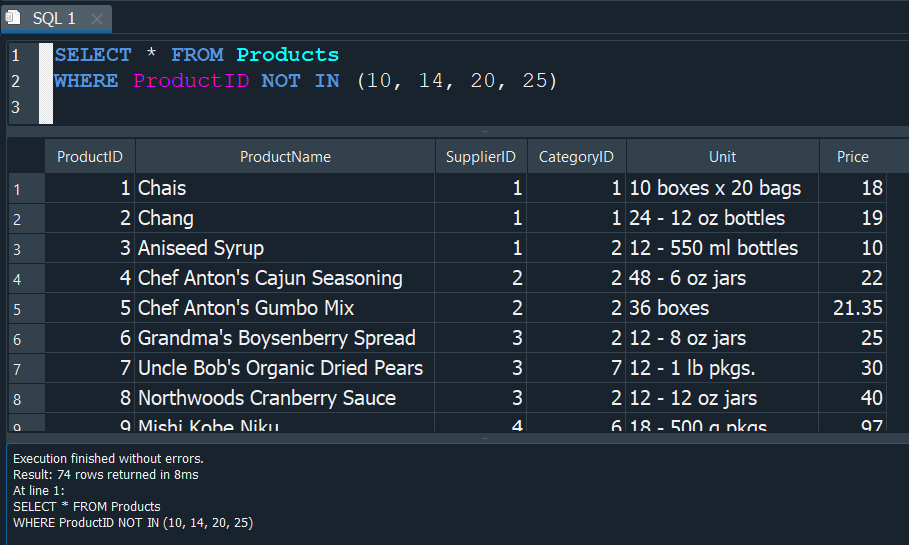
COMENTARIOS EN SQL #
En SQL como en distintos lenguajes de programación usamos los comentarios para añadir una descripción al proposito de nuestro codigo.
COMENTAR UNA LINEA #
En SQL usamos los -- para poder comentar una linea de codigo. /*COMENTARIO*/ si queremos comentar varias lineas.
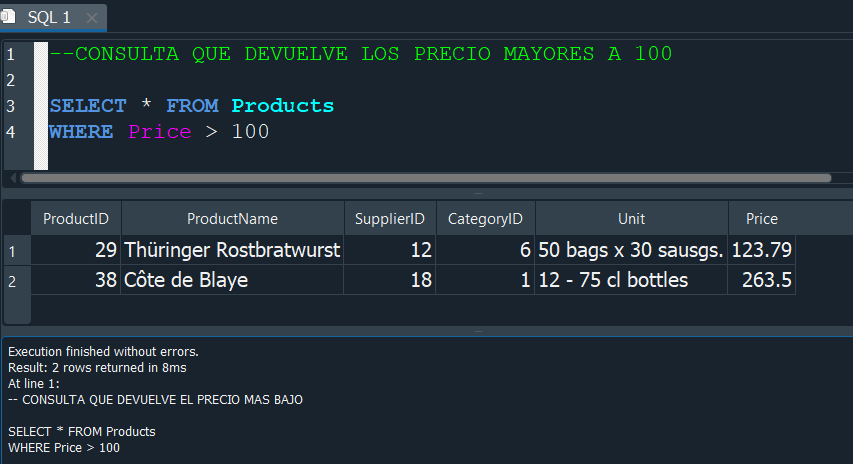
COMENTAR VARIAS LINEAS #
Si queremos comentar varias lineas de codigo usamos /*COMENTARIO*/.
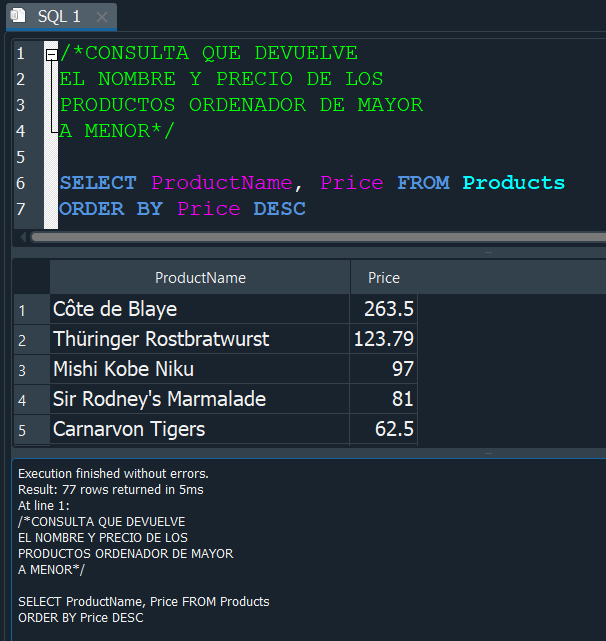
FUNCIONES DE AGREGACION #
Las funciones de agregación nos permiten efectuar operaciones sobre un conjunto de resultados, pero devolviendo un unico valor para todos ellos. En palabras mas simples nos permite obtener la media, maximos, minimos, sumantorias entre otras operaciones.
Estas funciones se utilizan con la clausula SELECT.
Veamos a continuación algunas de estas funciones:
FUNCION SUM #
La función SUM nos devuelve la suma de los valores de un campo que especifiquemos, cabe mencionar que solo podemos usar esta función en valores numericos.
Por ejemplo si deseamos sumar todos los precios Price de la tabla Products, emitiriamos la siguiente consulta:
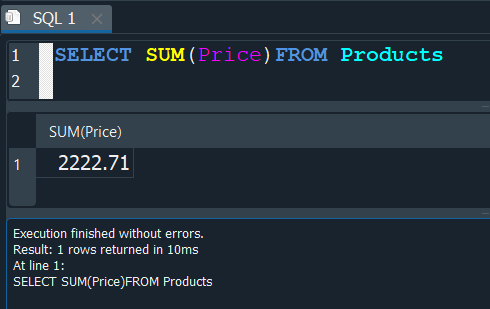
Donde dentro de los () de la función SUM, especifiriamos el campo el cual queremos sumar.
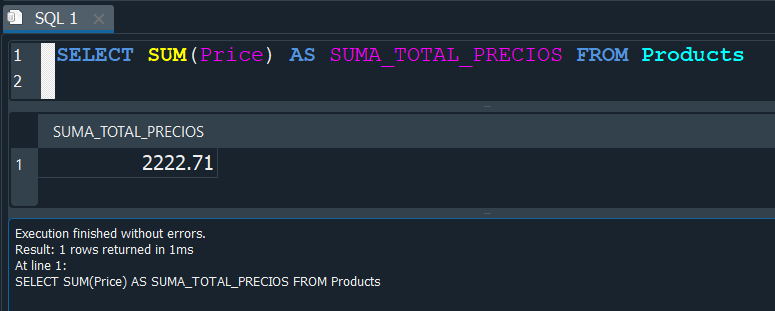
Aqui para tener una apreciación mejor podriamos crearnos un ALIAS y establecer el nuevo campo como SUMA_TOTAL_PRECIOS.
FUNCION COUNT #
Esta función nos devuelve el numeros total de las filas seleccionadas.
De la misma manera debemos especificar dentro de () el campo cuando agregemos la función COUNT.
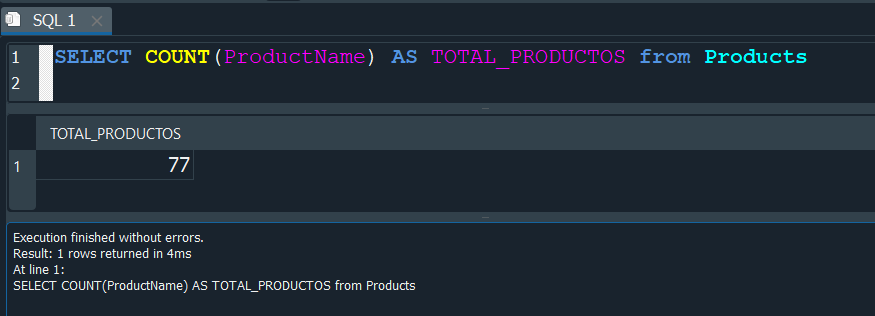
La consulta nos devuelve el total de filas del campo ProductName.
FUNCION MIX #
La función MIN nos devuelve el minimo valor de un campo.
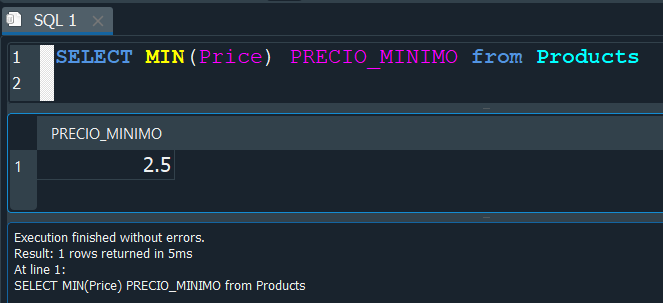
Al aplicar la función en el campo Price, obtenemos el valor del precio minimo.
FUNCION MAX #
Max nos devuelve el maximo valor del campo espeficado.
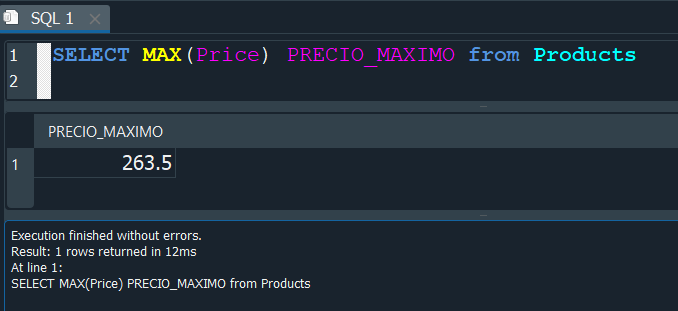
Aplicando la función en el mismo campo Price, obtenemos el valor del precio maximo.
FUNCION AVG #
La función AVG, nos devuelve como resultado el promedio del campo que especifiquemos.
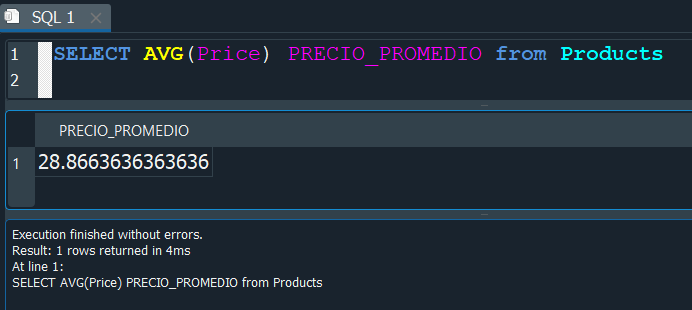
Como se resultado obtenemos el promedio de los precio de el campo Price, pero vemos que nos muestra un valor con muchas decimales, en ese caso podemos utilizar la función ROUND para redondear el valor.
FUNCION ROUND #
Como mencionamos anteriormente esta función nos va a redondear un valor, dandonos como resultado el valor entero.
Podemos aplicarlo a nuestra consulta anterior donde obteniamos el promedio, para que nos devuelva un valor entero.
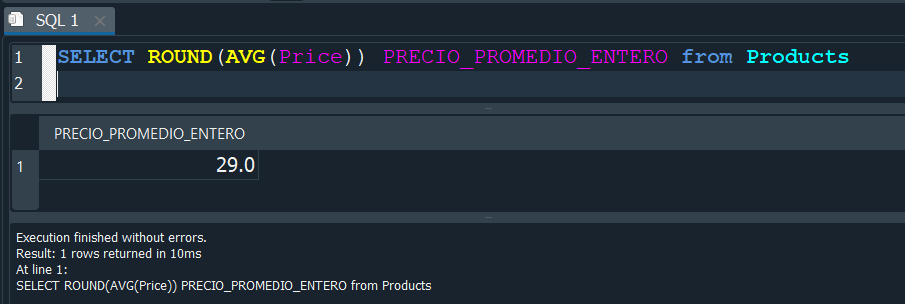
Aplicamos ROUND encima de la función AVG y obtenemos el promedio redondeado.
Estas funciones mencionadas son las basicas de
SQLy ademas las mas utilizadas, ya que cada gestor ofrece su propio conjunto mas amplio con otras funciones mas particulares.
CLAUSULA GROUP BY #
La clausula GROUP BY, la utilizamos para agrupar uno o varios registros segun uno o varios valores de la columna.
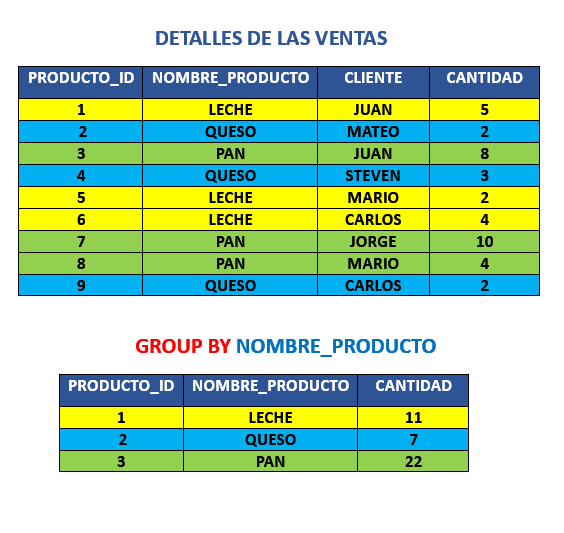
Como vemos a continuación tenemos el detalle de las ventas de los productos, pero si nosotros qusieramos obtener la cantidad de ventas por producto. En este caso usariamos la clausula GROUP BY y de este modo obtendriamos un ordenamiento de cada producto segun su cantidad.
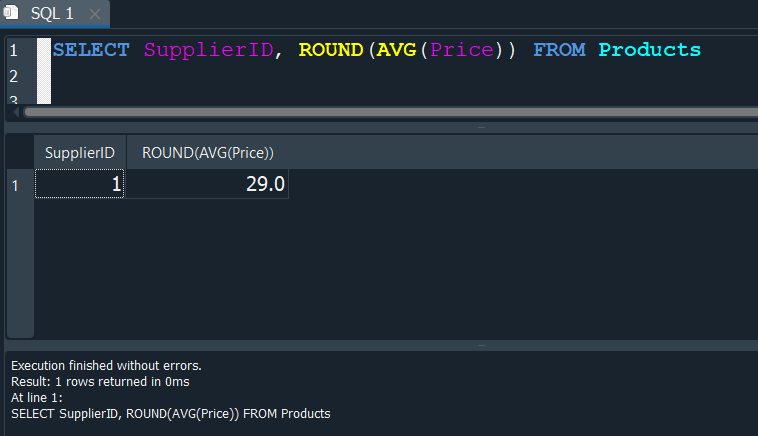
Supongamos que queremos obtener el promedio del precio de lo que cuestan los productos que ofrece cada proveedor.
Primero seleccionaremos el campo id del proveedor SupplierID y el promedio redondeado de la tabla Products. Esto nos dara como resultado el promedio total de los productos y el id que nos mostrara sera el primero, ya que como estamos usando una función de agregación esta solo devuelve un unico valor.
Y si ahora utilizamos GROUP BY en el campo SupplierID, lo que hara sera agruparnos por cada uno de los SupplierID correspondientes a cada proveedor.
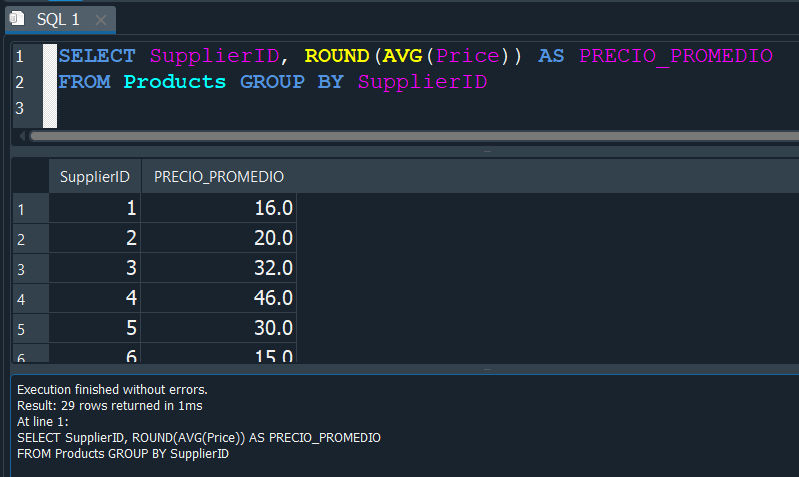
Como resultado obtendriamos el promedio del precio Price de los productos que ofrece cada uno de nuestros proveedores.
Y que hacemos si ahora que obtuvimos el promedio queremos verlos en orden. Pues simplemente como vimos anteriormente agregaremos a nuestra consulta un ORDER BY DESC y de esta manera verias los promedios ordenador de mayor a menor.
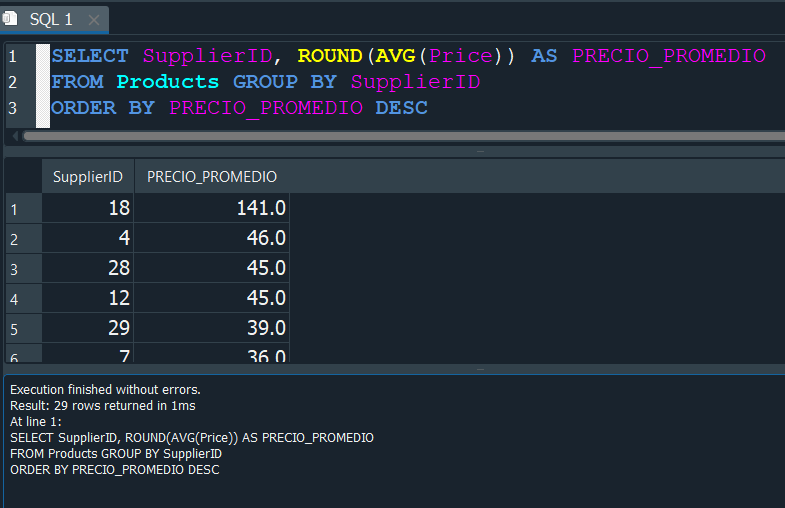
Ahora que pasa si queremos usar una condición en esta consulta, donde solo nos muestre el promedio PRECIO_PROMEDIO obtenido, pero solo si es mayor a 40.
Entonces automaticamente uno pensaria en usar una condición WHERE, pero esta nos arroja un error.
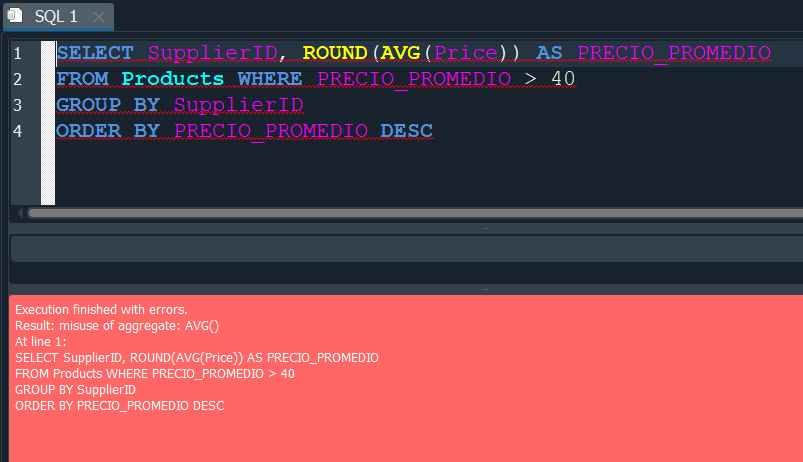
Seguro te preguntaras por que me esta arrojando un error si estoy estableciendo una condición correctamente?
Pues esto se debe a que WHERE trabaja haciendo un filtro de registros y en este caso al estar trabajando con GROUP BY y con una función de agregación, pasariamos a estar trabajando con grupos y por ese motivo WHERE en este caso siempre nos daria un error.
CLAUSULA HAVING #
Anteriormente mencionamos que al trabajar con GROUP BY, pasariamos de tratar con registros a hacer un filtrado por grupos. Por tanto asi como WHERE realiza un filtrado por registros, cuando queremos ejecutar condiciones en grupos usamos la clausula HAVING que funciona exactamente igual a WHERE pero cabe mencionarlo nuevamente lo usamos cuando trabajamos con grupos.
Por lo tanto recordando nuestra anterior consulta donde queriamos que se nos muestre PRECIO_PROMEDIO, pero solo si este era mayor a 40, nuestra consulta seria la siguiente.
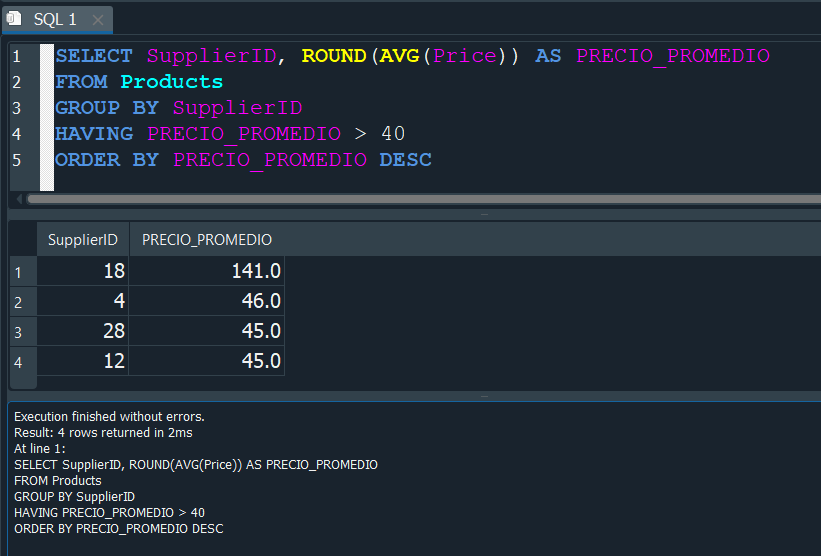
Veamos un nuevo ejemplo para que nos quede completamente claro. Vamos a suponer que queremos obtener cual fue el producto mas vendido del total de ventas.
Para ello usaremos la tabla de los detalles de la orden OrderDetails, donde seleccionaremos el campo de ProductID y el de Quantity.
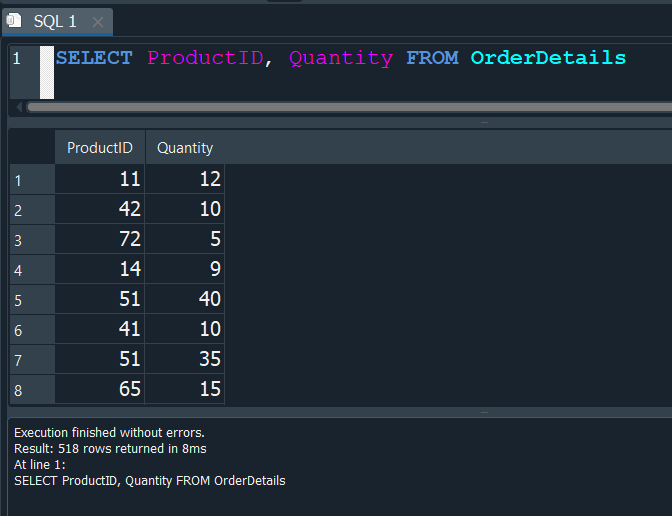
Despues aplicaremos la función de agregación SUM() para sumar las cantidades Quantity y las agruparemos con GROUP BY por el id del producto ProductID.
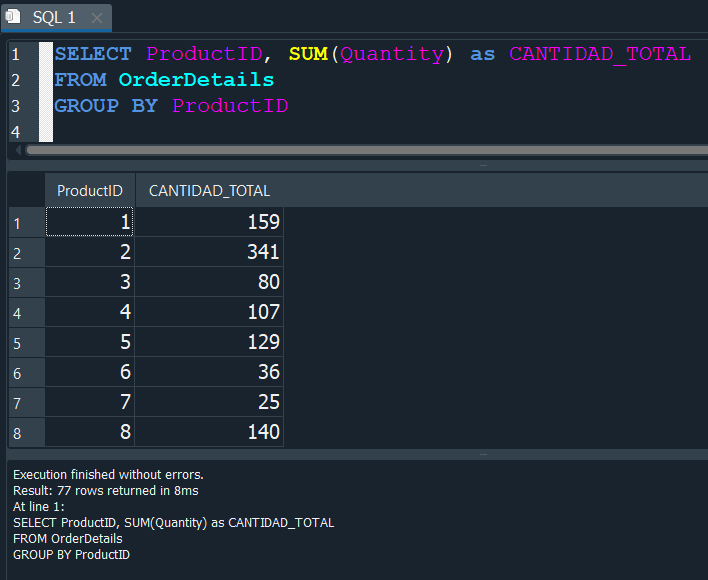
De esta manera obtendremos la cantidad de productos agrupados segun el id de producto ProductID.
Finalmente aplicaremos un ordenamiento ORDER BY por CANTIDAD_TOTAL de manera descendente y como solo queremos que se muestre el ProductID que mas se vendio usamos un LIMIT 1 y obtendriamos el resultado.
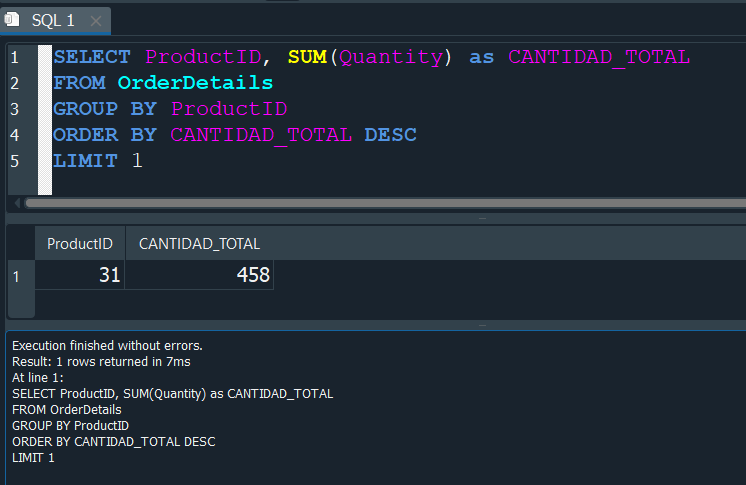
Bien ahora quiza te puedas preguntar por que añadimos un ORDER BY y despues un LIMIT si podriamos haber usado un HAVING para usar una condición donde en base a CANTIDAD_TOTAL nos de el valor maximo empleando la función MAX.
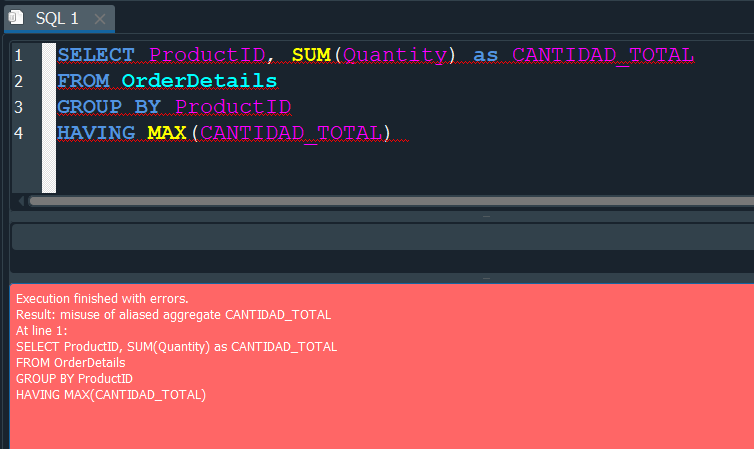
Vemos que nos arroja un error.
Esto se debe a que no es posible ejecutar una función de agregación sobre el resultado de otra función de agregación.
Asi que esa opción estaria descartada.
SUBCONSULTAS #
Hasta ahora hemos realizado consultas basandonos en una sola tabla, pero que pasa en los casos donde necesitemos juntas campos de distintas tablas para consultar algo concreto.
Pues en ese caso existen algunas maneras y una de ellas es utilizando las Subconsultas.
Para pode usar este concepto primero debemos entender el concepto de tablas relacionales y si queremos trabajar con datos de varias tablas a traves de una relación debemos usar los deintificadores.
Anteriomente gracias a las consultas GROUP BY y HAVING, pudimos agrupar por los identificadores y encontrar el producto que fue mas vendido. Pero si nos ponemos a analizar, el hecho de saber cual producto se vendio mas, no quiere decir que fue el que mas ganancias nos dio.
Y si quisieramos saber cual producto nos genero mas ingresos, en este caso tendriamos que relacionar las tablas OrderDetails y Products.
Aqui es donde podemos usar el concepto de Subconsultas que no es mas que una consulta dentro de otra consulta, es decir viene a ser una consulta que hace referencia a otra consulta.

Cuando realizamos una consulta esta nos devuelve un valor , y una subconsulta como vemos en la imagen es realizar una nueva consulta de ese valor.
Una cosa a tener en cuenta es que una
Subconsultasolo puede ser unSELECTya que esta solo nos devuelven información y no alteran a la base de datos.
Vamos a verlo de manera practica, y vamos a realizar una consulta que ademas de mostrarnos el id del producto ProductIDy la cantidad Quantity, tambien nos muestre el nombre del producto ProductName.
Para ello primero seleccionaremos los campos ProductID y Quantity de la tabla OrderDetails
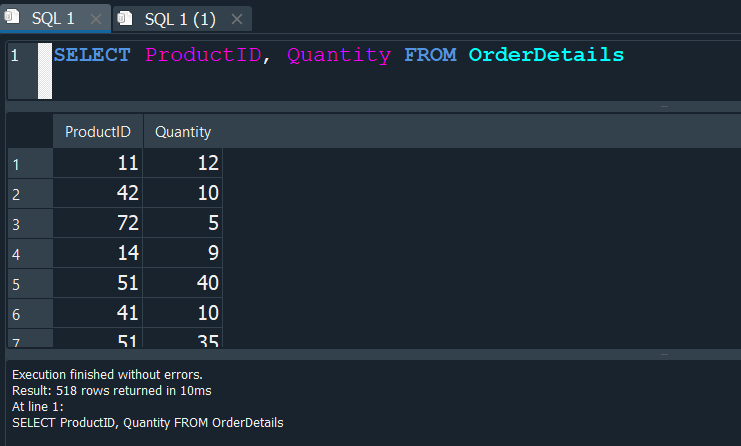
Ahora en una consulta aparte, vamos a seleccionar el campo faltante ProductName correspondiente a la tabla Products
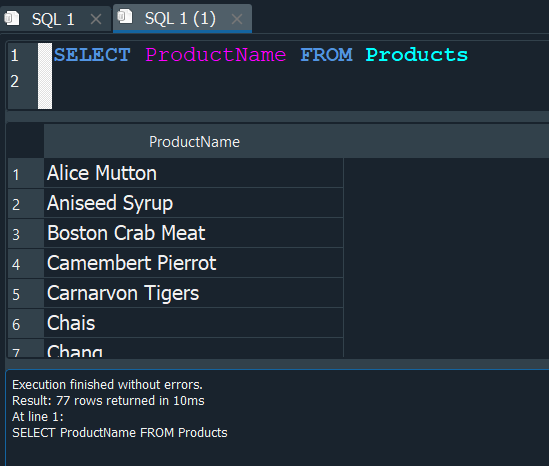
Esta consulta sera la que utilizaremos para realizar una subconsulta dentro de nuestra primera consulta.
Para ello debemos de integrarlo en nuestra consulta principal como un campo y ponerlo entre () y podemos ponerle el alias al que corresponde.
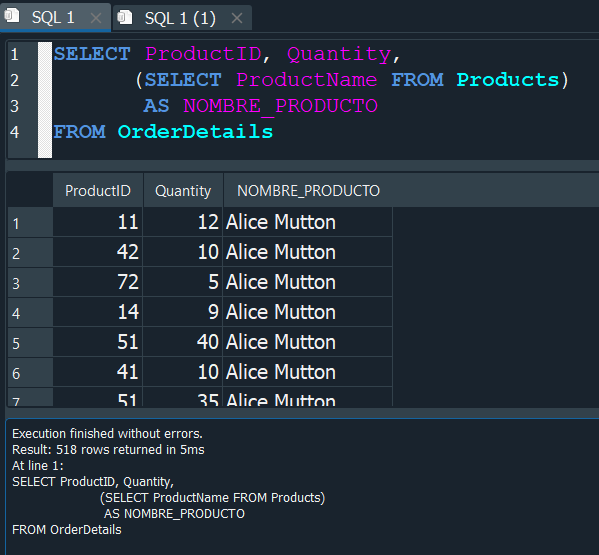
Podemos ver que si se nos esta incluyendo el campo, pero solo se nos muestra el primer resultado repetido. Esto se debe a que al ejecutar un SELECT, por cada ejecución nos esta deolviendo el primer campo, y por lo tanto dentro debemos de establecer una condición en la que comparemos que el ProductID de la tabla OrderDetails sea igual al del ProductID de la tabla Products.
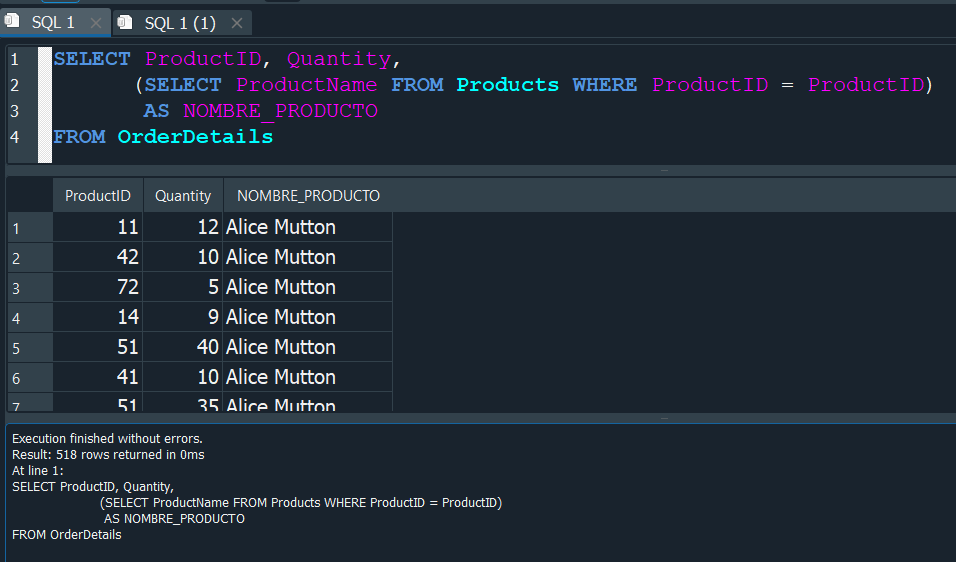
Ejecutamos la consulta correctamente, pero ahora vemos que nos vuelve a mostrar el mismo resultado. Y esto se debe a que dentro de la subconsulta no se sabe a que tabla esta haciendo referencia el ProductID, por lo tanto debemos especificar que esta haciendo referencia a OrderDetails.
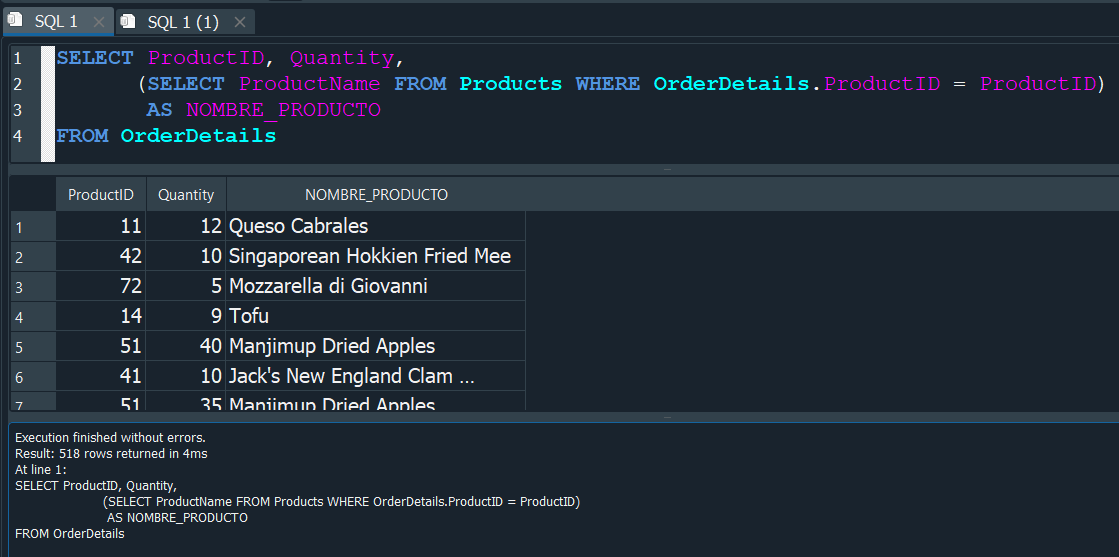
De esta manera vemos que ahora si, nos muestra los resultados correctamente.
Y si quiseramos adicionar mas campos, hariamos exactamente el mismo proceso solo especificando el nombres de los campos.
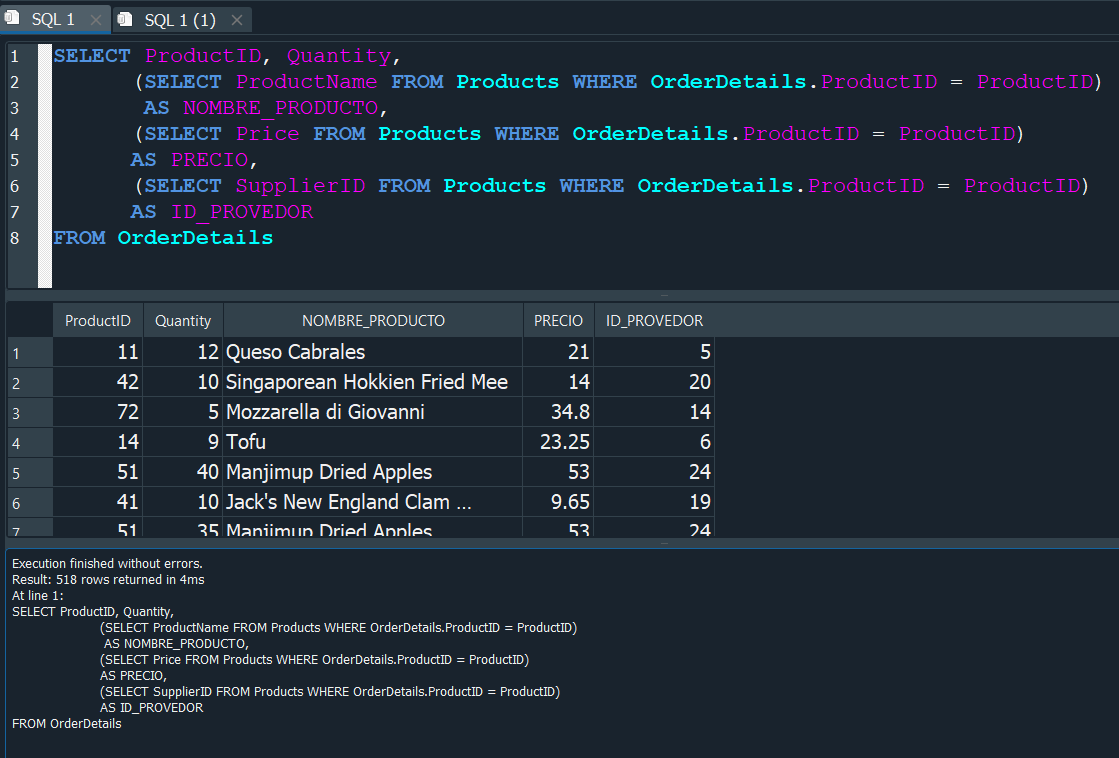
Ahora que ya comprendimos como funcionan las subconsultas, volvamos a resolver lo anteriomente propuesto en el que habiamos obtenido el producto que se vendio en mayor cantidad, pero no el que mas ingreso nos genero.
Teniamos previamente la CANTIDAD_TOTAL.
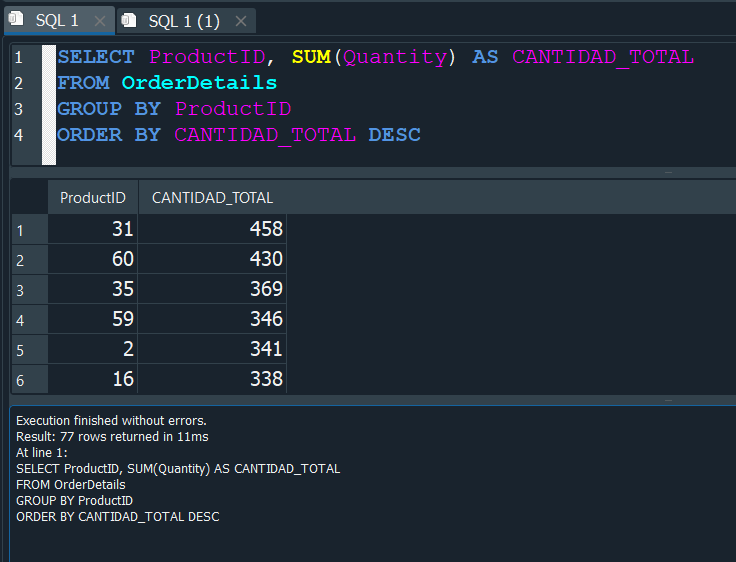
Ahora debemos agregar la subconsulta que nos devuelva el precio Price, podemos usar un alias para acortar el nombre de la tabla OrderDetails como OD.
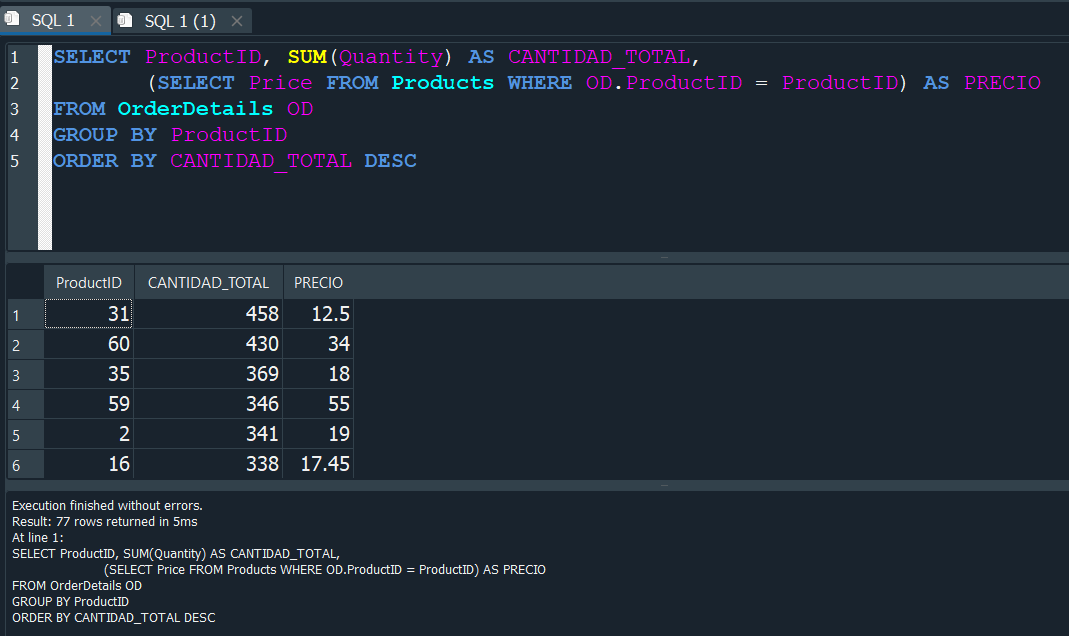
Ahora solo nos faltaria calcular el monto total e ingreso, para ello tendriamos que multiplicar la CANTIDAD_TOTAL por el PRECIO, pero debido a que no podemos usar un ALIAS, necesariamanete debemos insertar nuevamente la subconsulta que nos generaba el alias y de la misma manera tambien insertar la función de agregación, adicionalmente agregaremos el NOMBRE_PRODUCTO para verlo mas descriptivo.
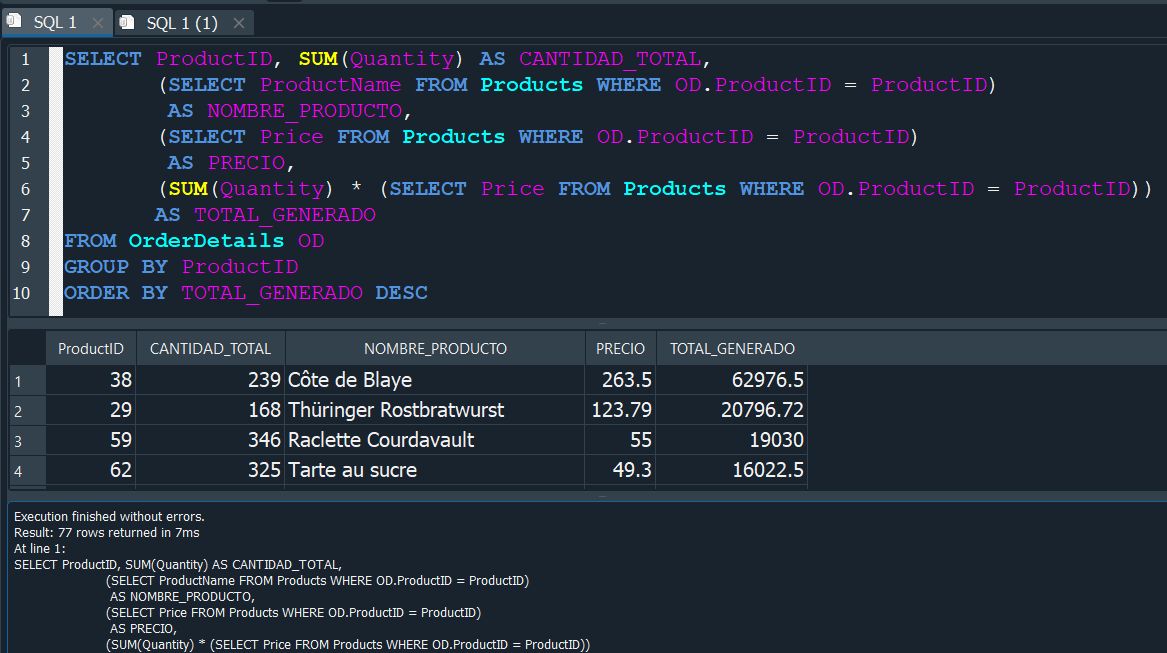
Y en conclusión vemos que el producto que mas se vendio, no necesariamente corresponde al que mas ingresos nos aporto.
Otra cosa acerca de las subconsultas, es que tambien las podemos usar en condicionales como un WHERE, para realizar operaciones con un campo sin necesidad de mostrarlo.
Para ello vamos a modificar nuestra consulta anterior y borrar el campo que correspondia a el PRECIO y utilizarlo para establecer una condición donde solo nos devuelva los precios mayores a 100.
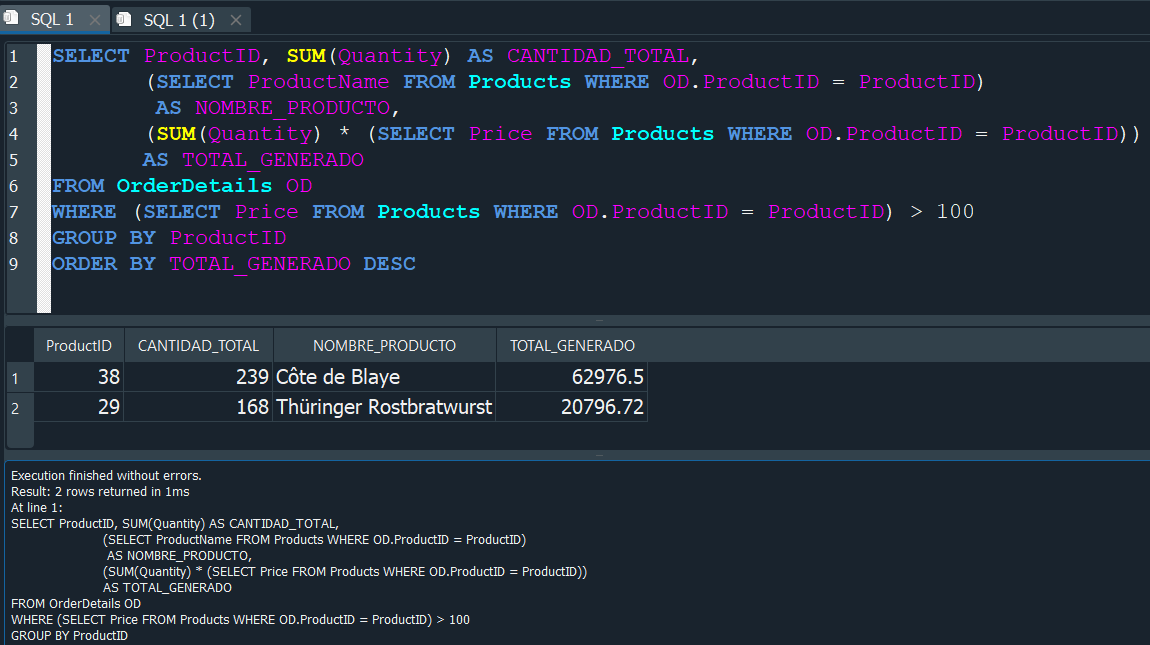
Algo muy intersante a mencionar es que el resultado de esta subconsulta, nos devuelve una especie de tabla virtual en la que podemos seguir trabajando. Ya que nuestra subconsulta anterior, podemo meterla dentro de un SELECT y volver a trabajar desde ahi como si fuera otra tabla mas simplificado.
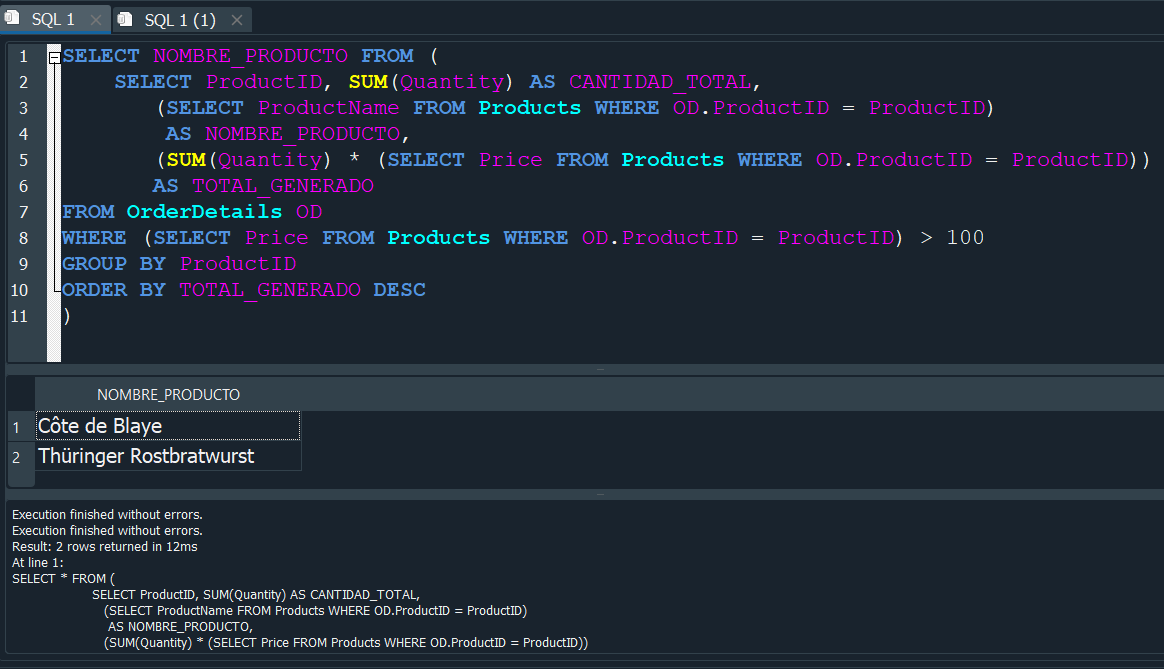
De esta manera podemos trabajar en ella como si fuera otra tabla, como en este caso seleccionando el campo NOMBRE_PRODUCTO.
Intentemos realizar algo mas complejo usando subconsultas, como mostrar el total de ordenes realizadas por los clientes, siempre y cuando estas sean mayores a su promedio.
Par ello primero tenemos que seleccionar el nombre CustomerName de la tabla empleados Employees y dentro ejecutaremos una subconsulta que nos muestre la suma de la cantidad de ordenes SUM(Quantity) esto de la tabla OrderDetails y de la tabla Orders.
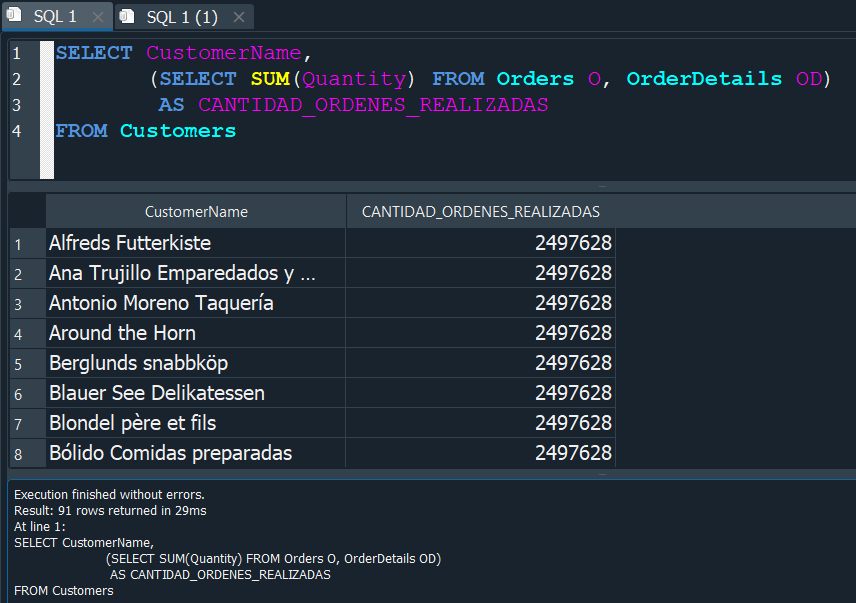
Esto nos devolvera la CANTIDAD_DE_ORDENES_REALIZADAS, pero con solo un valor muy grande referido a la cantidad total de ordenes despues de realizar una especie de multiplicación como un producto cartesiano que no es la correspondiente y para poder obtener el valor verdadero. Debemos de establecer una primera condición donde el CustomerID de la tabla Customers sea igual al de la tabla Orders.
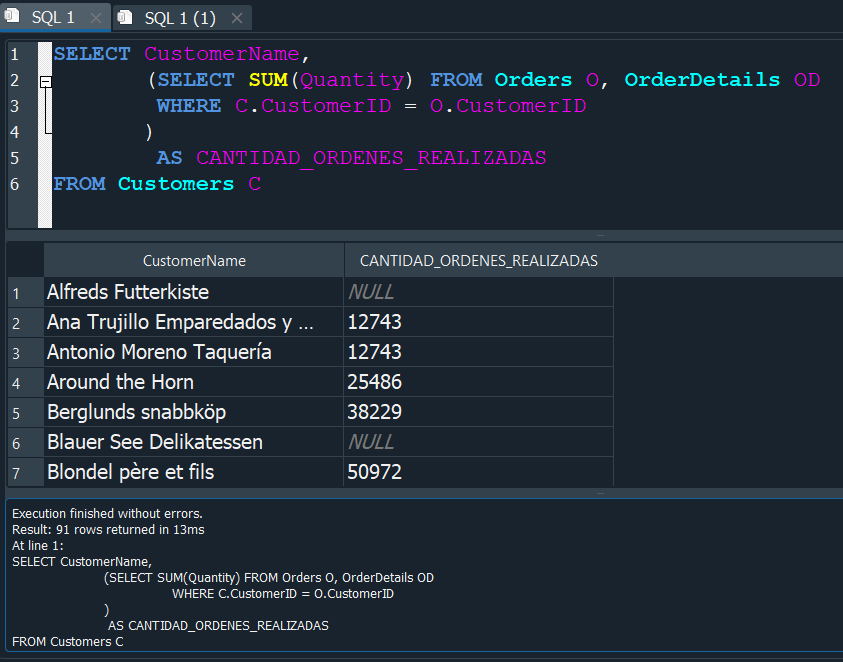
Ahora tambien debemos validar que el id de la orden OrderID de la tabla Orders y OrderDetails sea el mismo, y de esta manera obtendriamos la cantidad total de ordenes realizadas por nuestros clientes Customers.
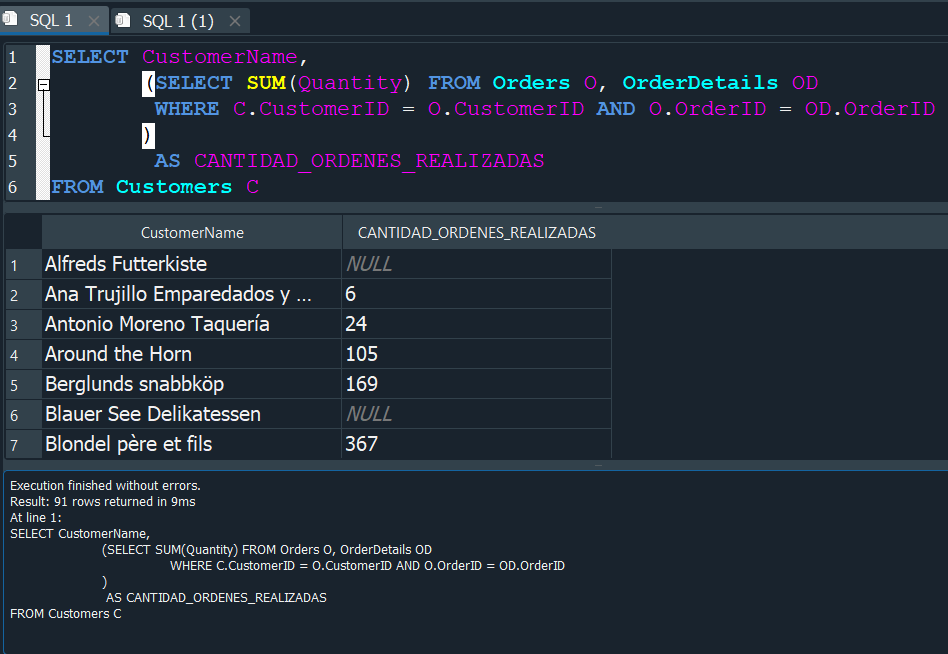
Ya llegados a este punto queremos que solo nos muestren los resultados que sean mayor al promedio de ordenes.
Para esto tenemos que recordar lo anteriormente mencionado de que podemos efectuar subconsultas en un WHERE, por ello primero buscaremos calcular el promedio del total de ordenes de el resultado de una subconsulta a la que llamaremos CANTIDAD_TOTAL_ORDENES proveniente de la tabla Customers al cual asignaremos como alias C2 para evitar problemas ya que contamos con una denombre C1.
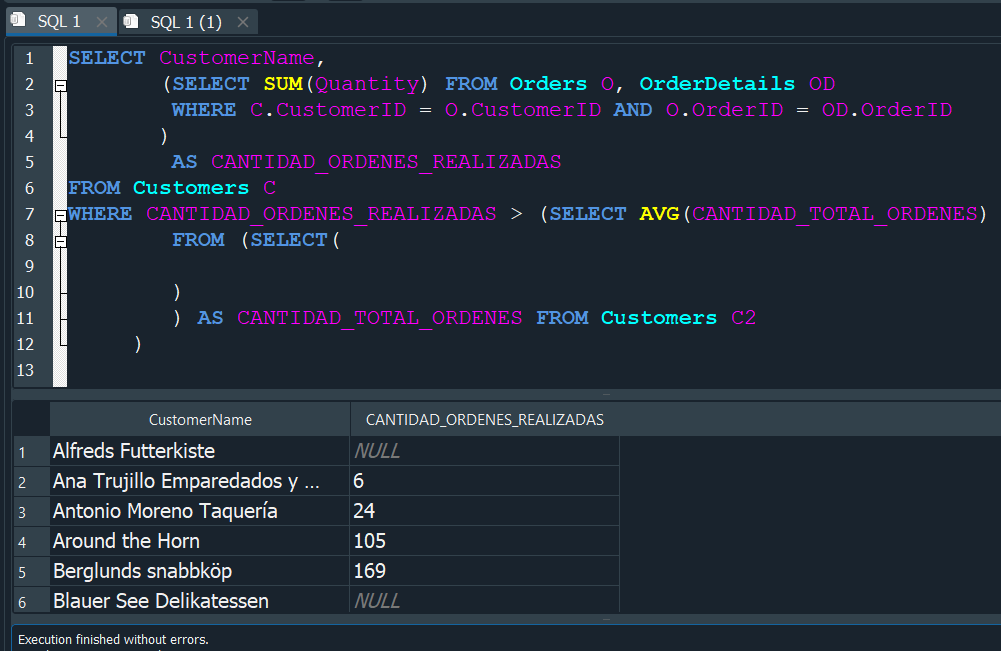
Y dentro de esa subconsulta vamos a insertar la primera subconsulta que realizamos con la cual obteniamos la CANTIDAD_ORDENES_REALIZADAS, solo que esta vez provendra de la tabla Customers con el alias C2.
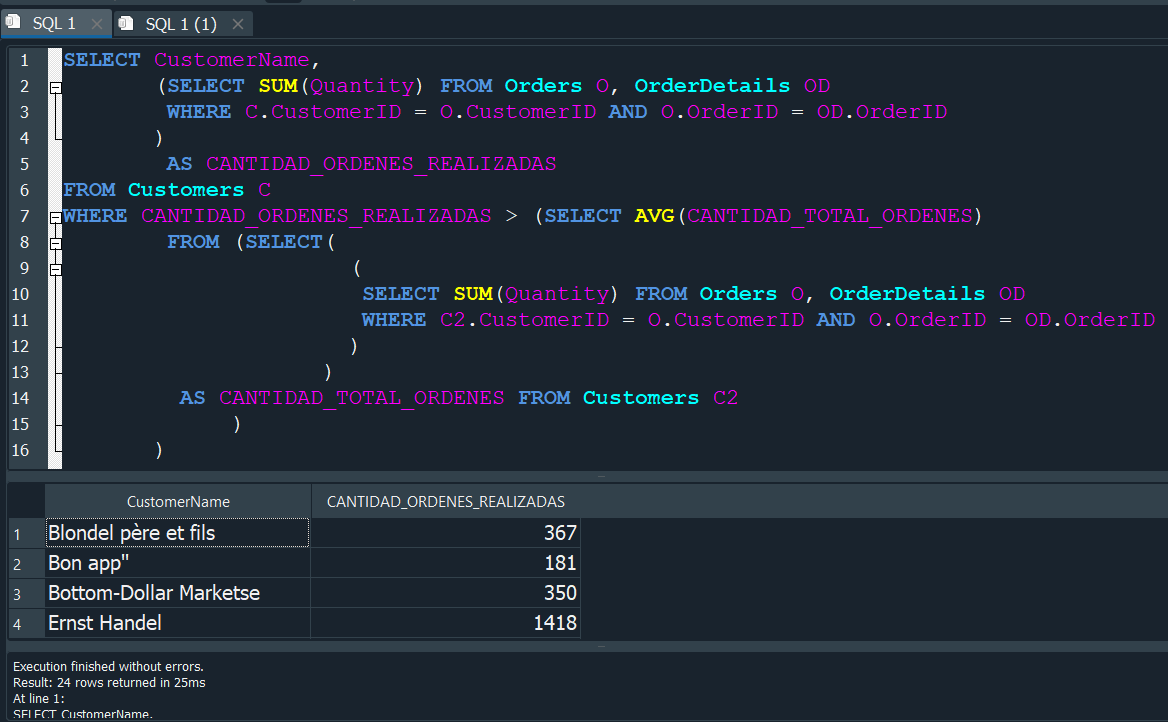
Asi con el uso de subconsultas, lograriamos obtener el resultado donde la CANTIDAD_ORDENES_REALIZADAS son mayores al promedio.
Con esto concluimos que podemos usar las subconsultas en ciertos casos, pero existe una forma mejor de poder realizar estas acciones y nos eviten tener un codigo tan extenso como el que generamos y estos vendrian a ser los JOINS de los cuales hablaremos a continuación.
JOINS #
Son operaciones que realizamos para combinar los datos de dos o mas tablas de nuestra base de datos, pero que esta información se devuelva en una tabla nueva.
Existen varios tipos de JOINS y entre los principales tenemos cinco:
CROSS JOIN #
Son el resultado de unir dos tablas, como si se tratase de un producto cartesiano.
Supongamos tenemos dos tablas, una de estudiantes y otra de lenguajes, si aplicaramos un CROSS JOIN daria como resultado el producto cartesiano de ambas tablas.
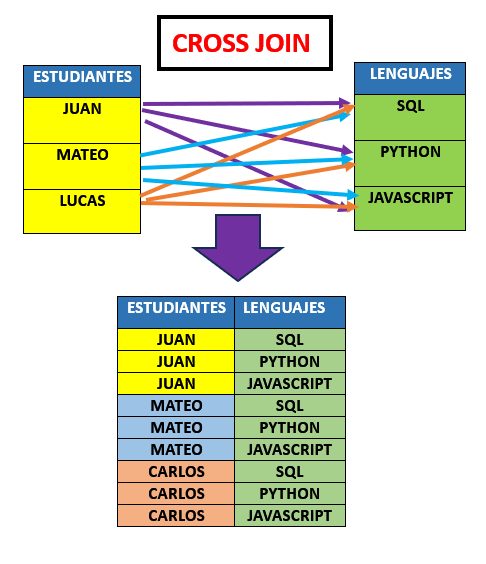
Existen dos formas de definirlos, las cuales son implicita y explicita.
Implicitamente cuando definimos un CROSS JOIN, pero sin usar el termino JOIN.
Si lo aplicamos a las tablas de empleados Employees y ordenes Orders, nos da como resultado el producto cartesiano de ambas ya que nuestra tabla Employees tiene 10 registros y Orders 196, como resultado nos devuelve 1960 registro relacionados.
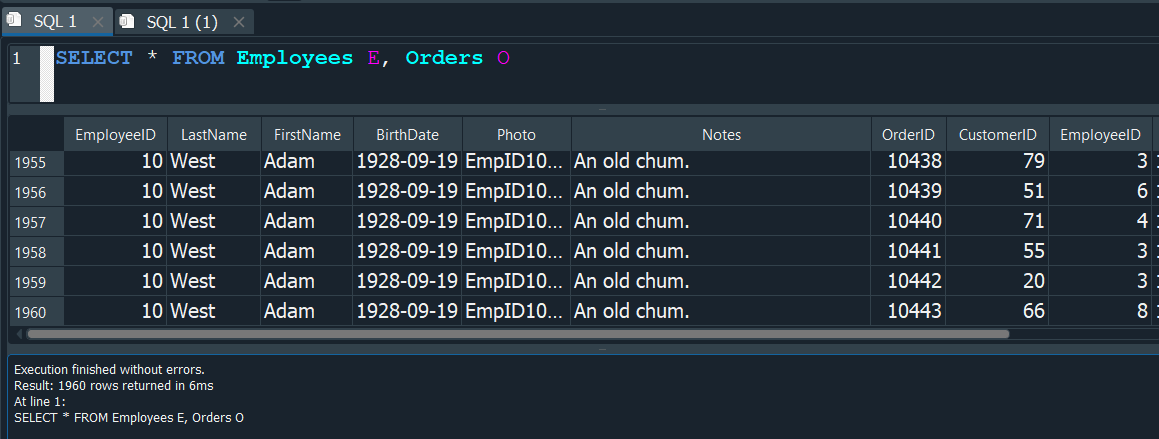
Tambien podemos obtener el mismo resultado si lo aplicamos de manera explicita, para ello varia un poco la sintaxis.
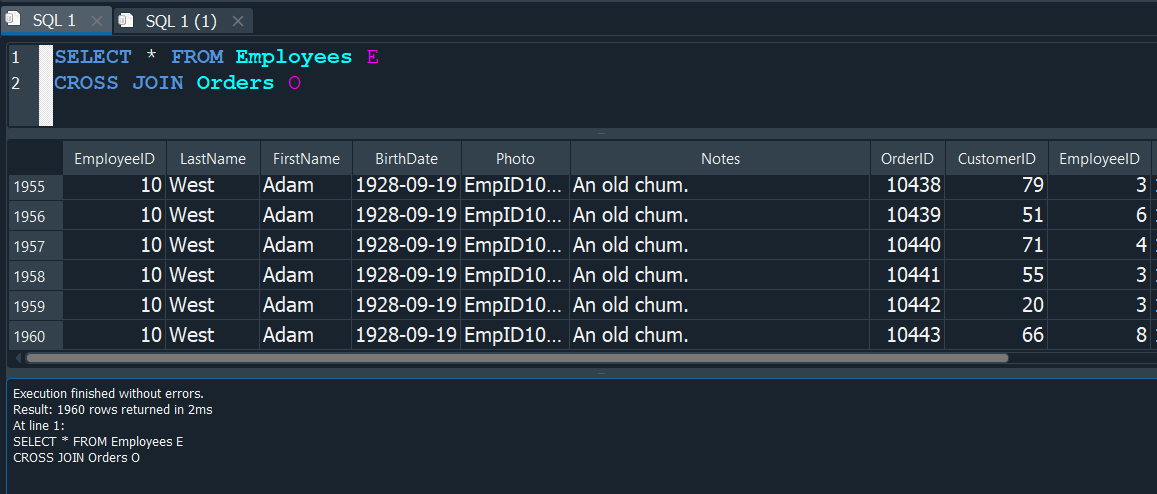
Este tipo de join casi no se usa, pero es recomendable conocer como funciona.
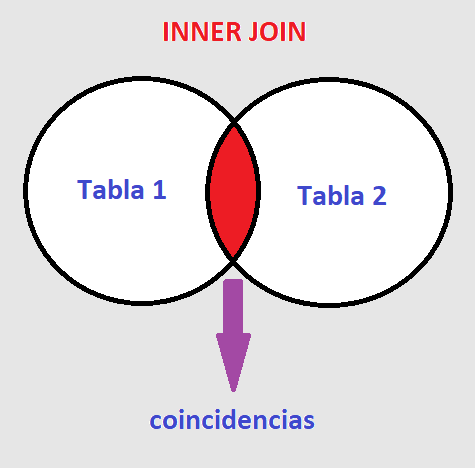
INNER JOIN #
Es el resultado de la busqueda de coincidencia de dos o mas tablas en función a la columna que tengan en comun.
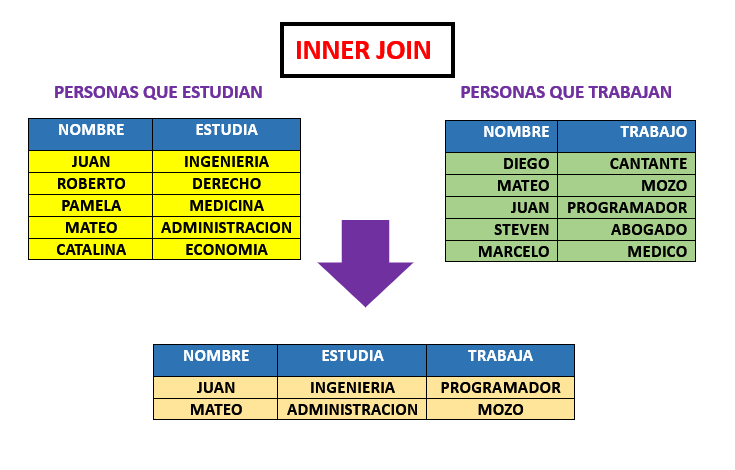
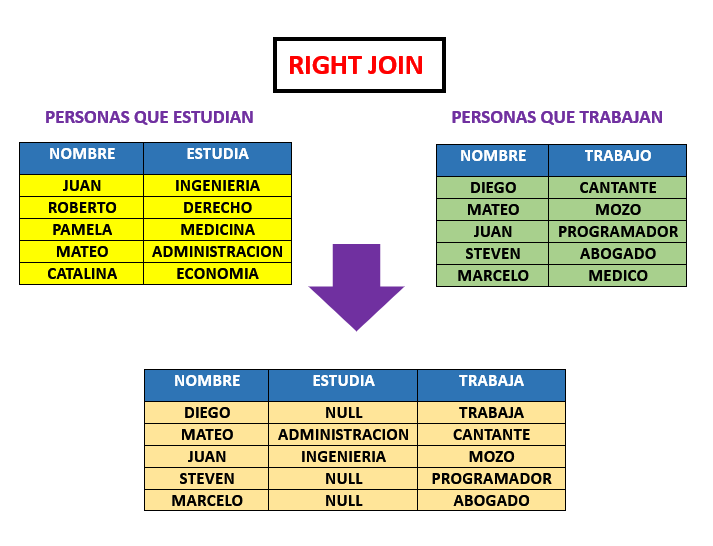
Supongamos tenemos dos tablas una de personas que estudian y otra de personas que trabajan, como resultado el INNER JOIN nos daria unicamente las coincidencias de ambas tablas donde las personas estudian y trabajan.
Para aplicarlo a nuestra tablas de empleados y ordenes, primero debemos seleccionar nuestra tabla Employees y seguidamente INNER JOIN con la tabla Orders y finalmente para ejecutar la concidencia usaremos ON especificando que queremos nos lo ejecute solo cuando el EmployeeID de ambas tablas sean iguales.
Esto nos dara como resultado una nueva tabla donde solo nos muestren los datos cuando coincidan los EmployeeID en ambas tablas.
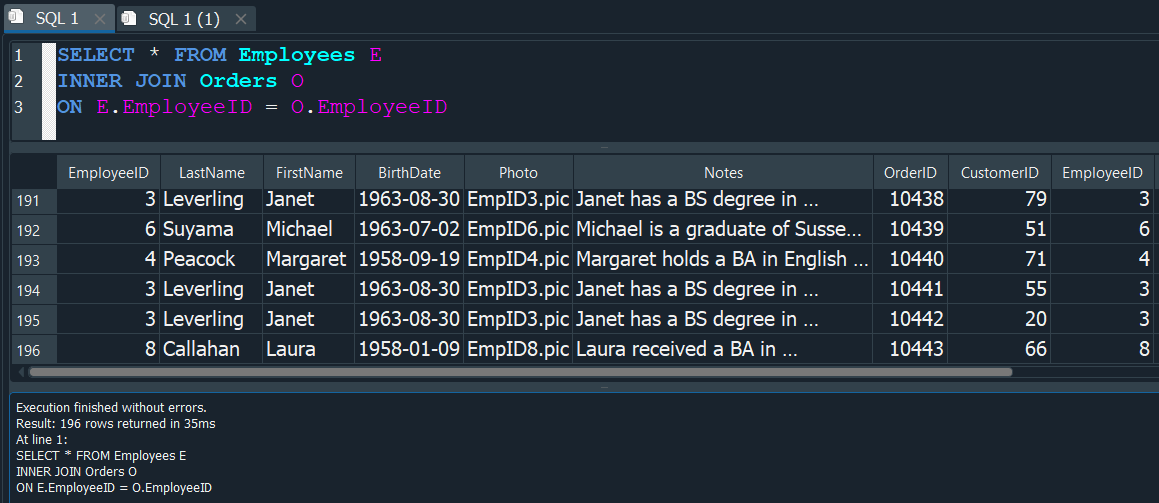
Para entenderlo mejor de manera practica, vamos a crearnos una tabla adicional con el nombre Gratificacion, en donde haremos referencia al EmployeeID.
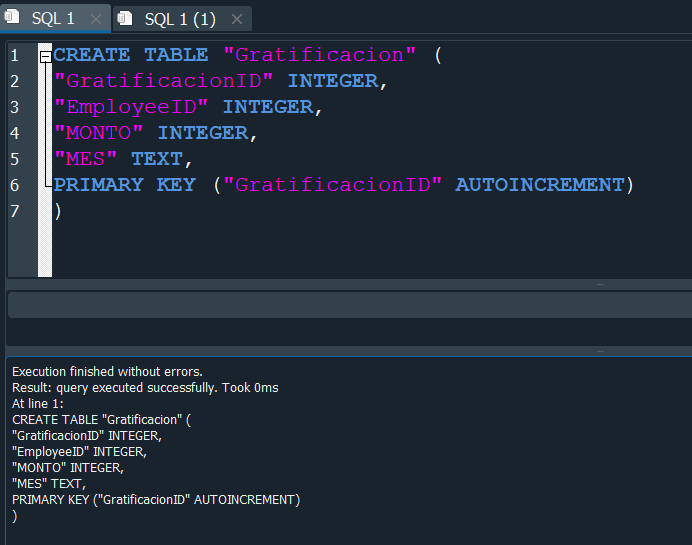
Ahora insertaremos algunos valores al azar para poder trabajar nuestro JOIN con esta tabla.
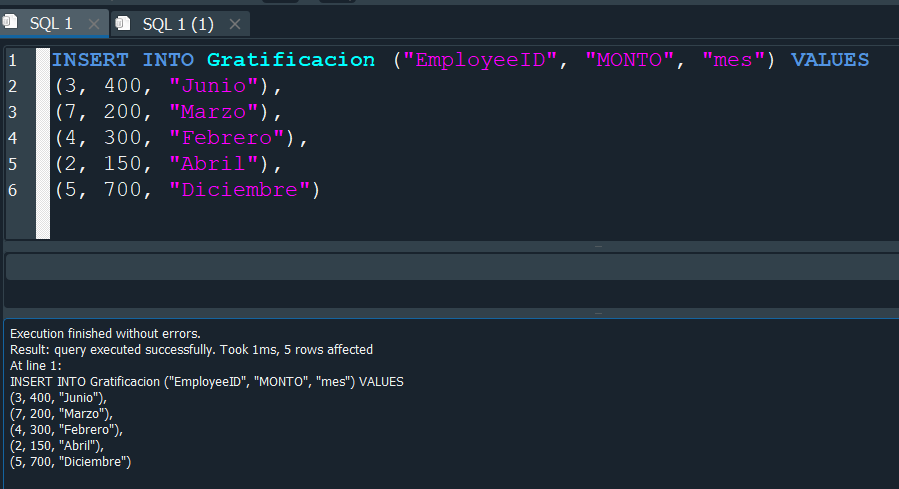
Adicional a ello insertaremos algunos valores NULL, para este caso.
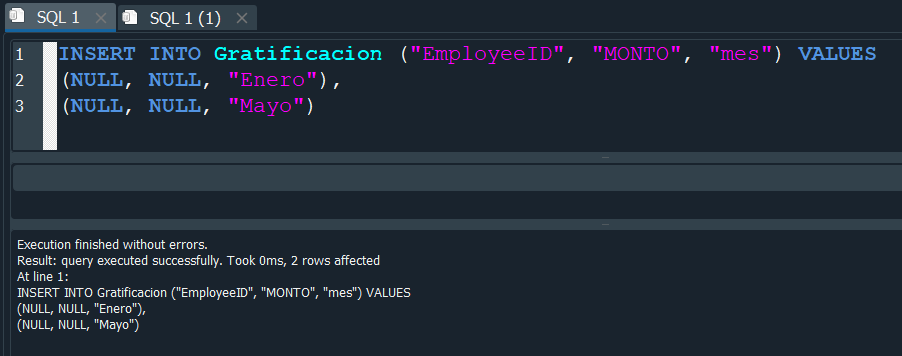
Nuestra tabla nos queda de la siguiente forma, donde podemos observar existen valores nulos.
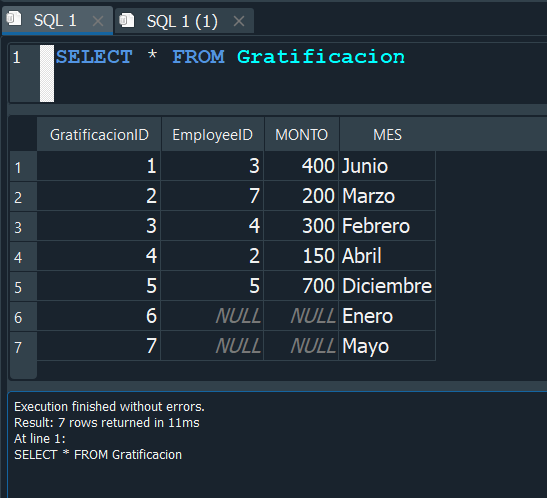
Ahora vamos a proceder a realizar un INNER JOIN, tomando como tablas Employees y Gratificacion.
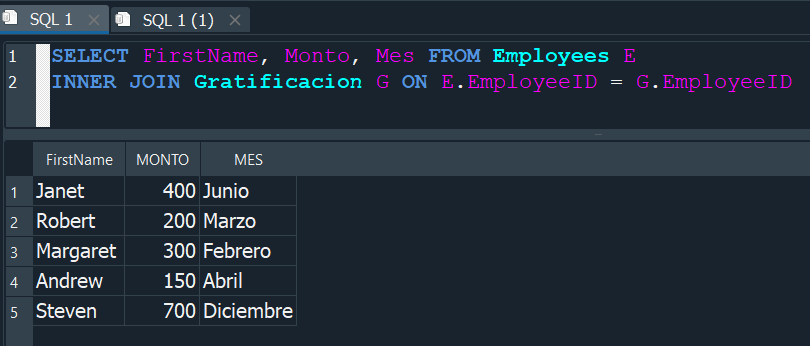
Como resultado, podemos ver que solo se nos muestran las coincidencias y no los valores NULL ya que estos al no coincidir con el EmployeeID no los concidera.
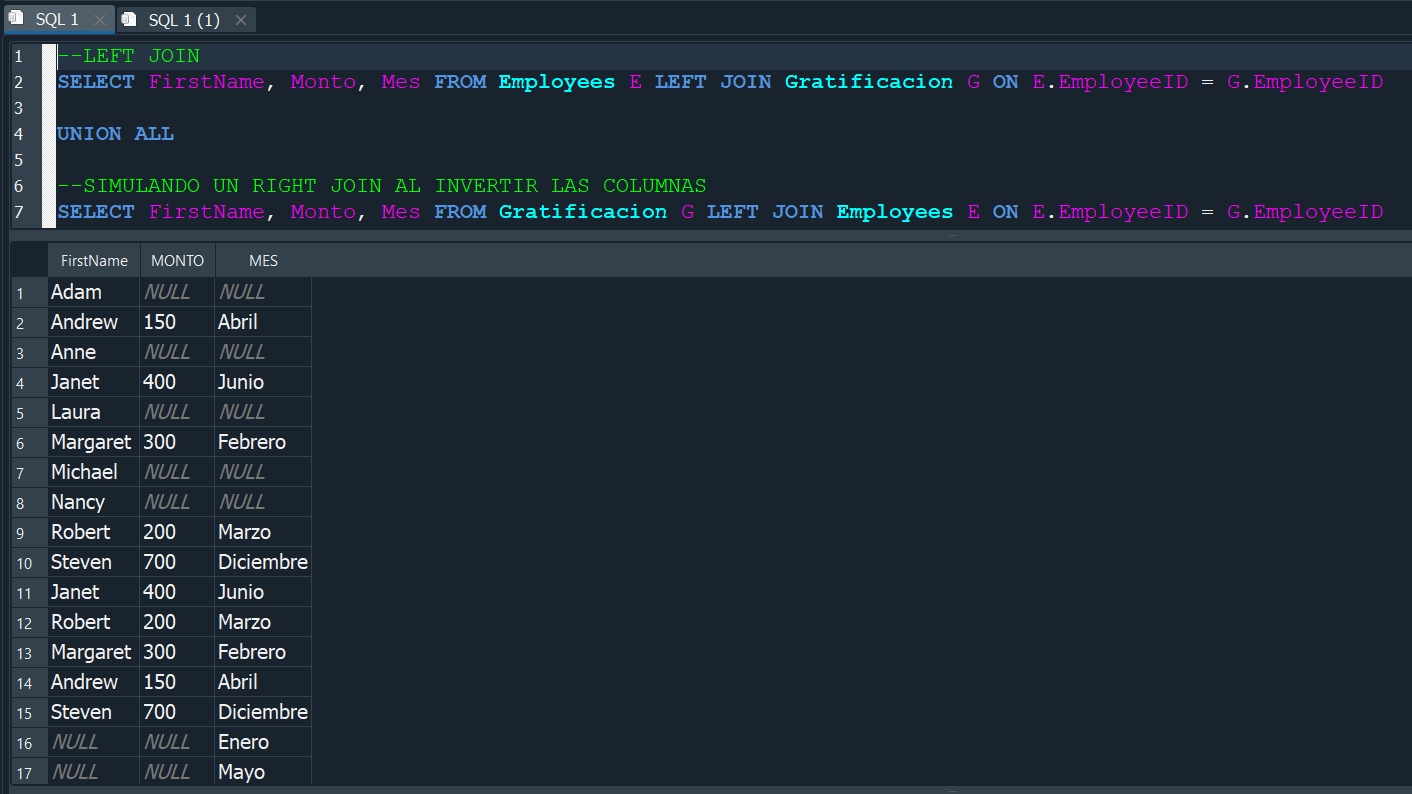
LEFT JOIN #
En el LEFT JOIN se toma como prioritaria a toda la tabla de la izquierda y solo una parte de la tabla derecha, concretamente solo si existe alguna coincidencia.
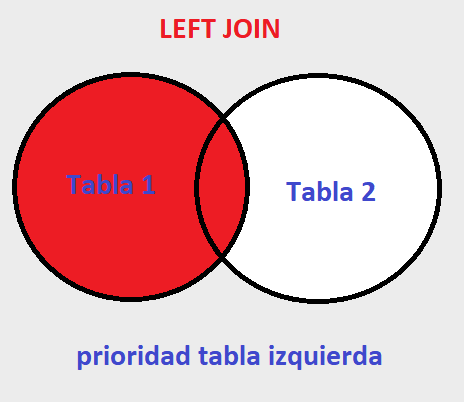
Usemos el mismo caso donde tenemos dos tablas de personas que estudian y otra de personas que trabajan, si aplicamos un LEFT JOIN, como resultado tendriamos todos los datos de la tabla personas que estudian con sus coincidencias y de no existir alguna se completaria con valores NULL.
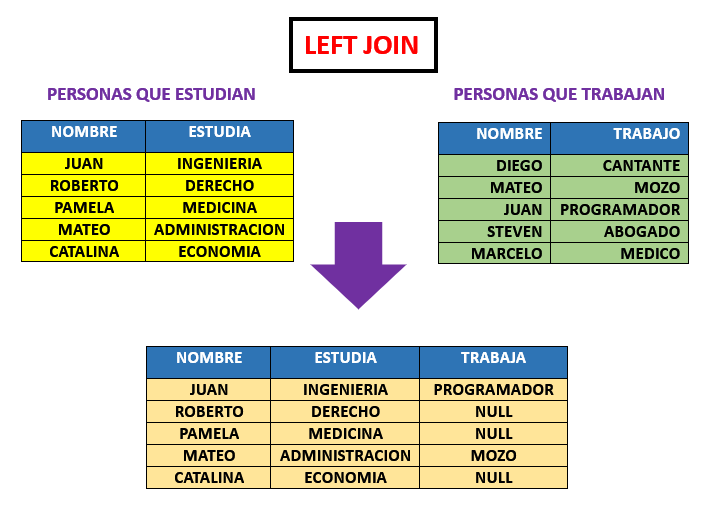
Si ahora lo vemos de manera practica y usamos en nuestras tablas Employees y Gratificacion, es muy simple ya que solo debemos cambiar la palabra inner por LEFT y igualmente para establecer la comparacion usamos ON.
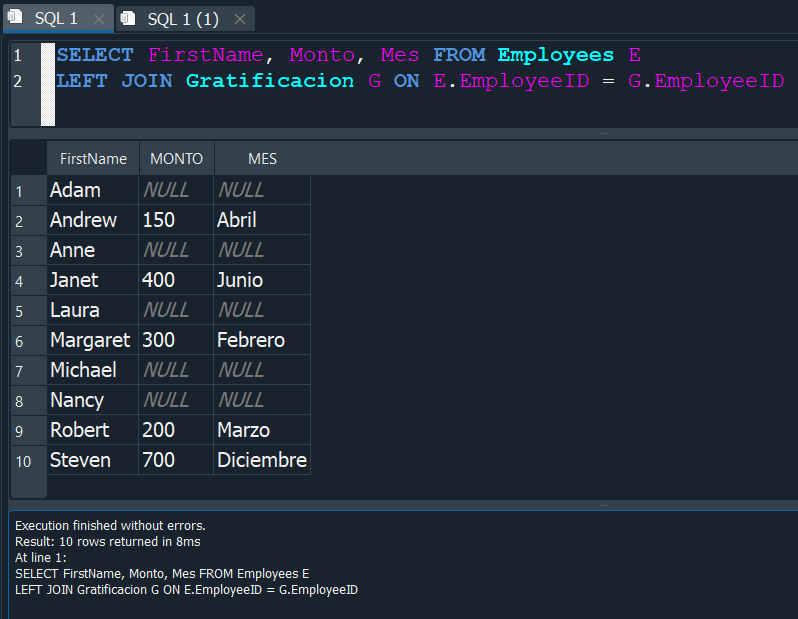
El resultado de la consulta nos muestra todos los valores de la tabla Employees y de la tabla Gratificacion solo los valores donde exista coindencias, y en las que no existan nos las completa con valores nulos.
RIGHT JOIN #
Similar al left join cuando usamos RIGHT JOIN, se toman todos los datos de la tabla derecha y solo parte de la izquierda.
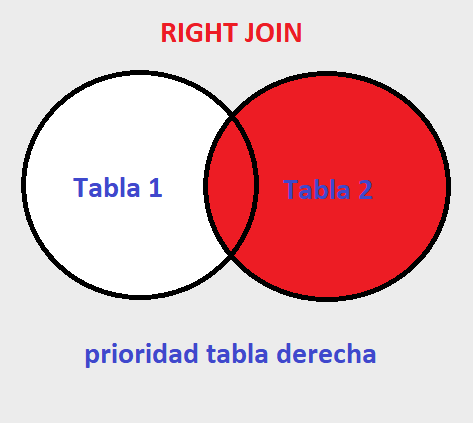
De la misma manera con nuestras tablas de persona que estudian y trabajan, al aplicar un RIGHT JOIN tendriamos como resultado todos los valores de la tabla derecha personas que trabajan y de no existir coincidencias de igual modo se completarian con datos de tipo NULL.
Aplicandolo nuevamente a nuestras tablas Employees y Gratificacion, seria muy parecido a lo anterior, solo que en este caso particular, sqlite3 no admite la función RIGHT JOIN, ya que si la tratamos de ejecutar nos genera un error.
Aunque en otros tipos de gestores esta opción si es valida, hay un manera logica y facil de solucionar esto en sqlite3 y es tan sencillo como aplicar un LEFT JOIN, pero cambiar el orden de las tablas y de esa manera es como si ejecutaramos un RIGHT JOIN.
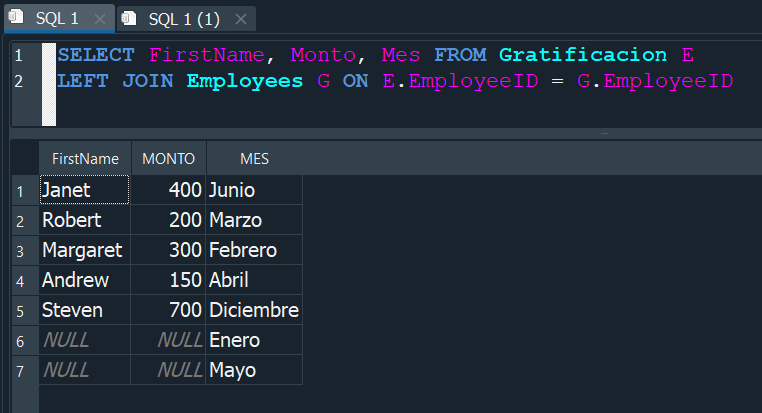
Y asi de una forma simple logramos aplicar un RIGHT JOIN que vendria mas o menos a ser un LEFT JOIN inverso .
FULL JOIN #
A diferencia que el left y right join, cuando aplicamos un FULL JOIN nos devuelve todo, es decir la suma de las tablas.
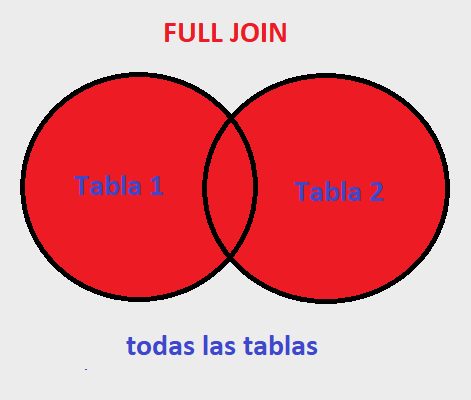
Es la union de todas las tablas, al aplicar un FULL JOIN, nos devuelve todos los valores de ambas tablas y no de existir coindencias entre algunos campos, de la misma manera nos los muestra con valores nulos NULL.
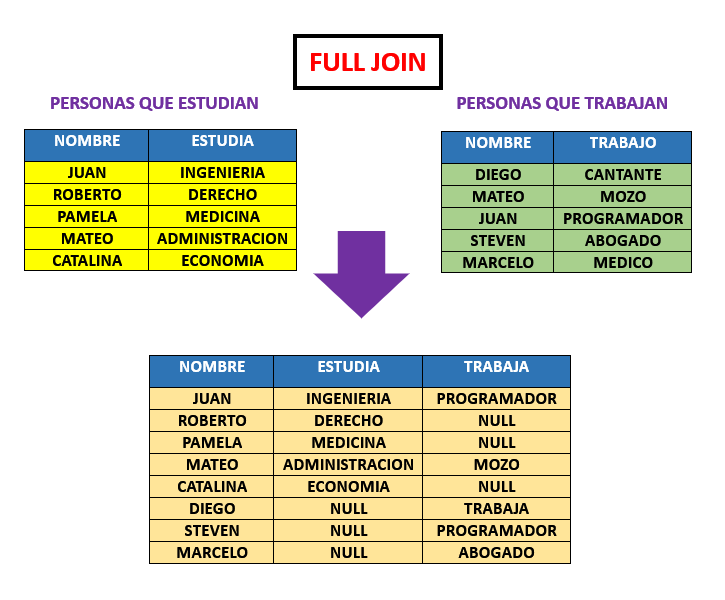
Para poder aplicarlo en sqlite3 de manera practica, tambien tenemos un problema puesto que tampo acepta la ejecución de FULL JOIN, pero para ello podemos usar una clausula
que nos permita unir tanto el LEFT JOIN como el RIGTH JOIN y esta tiene por nombre UNION.
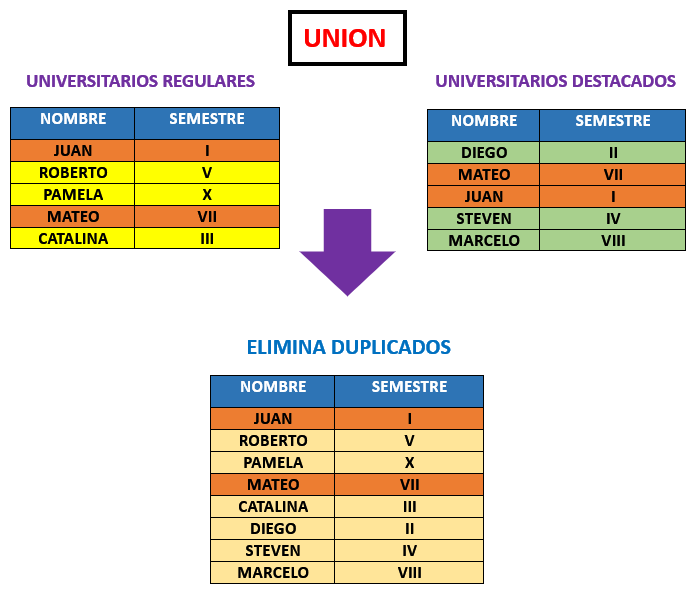
CLAUSULA UNION #
La clausula UNION la utilizamos para combinar el resultado de dos o mas consultas en un solo conjunto de datos.
Para poder usar esta clausula se deben tener la misma cantidad de columnas y los tipos de datos deben de ser compatibles.
Lo que hace concretamente UNION es la devolvernos una unica tabla que contenga las filas combinadas de las tablas, eliminando las duplicadas.
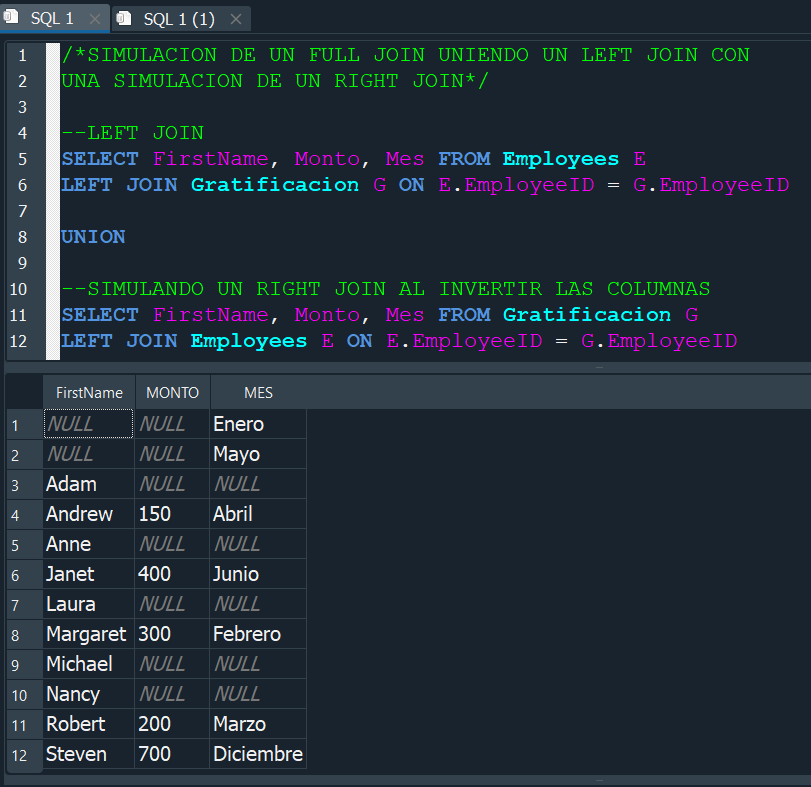
Si ahora ejecutamos un LEFT JOIN y un RIGHT JOIN, al unir ambas consultas con un UNION obtendremos como resultado un FULL JOIN simulado.
CLAUSULA UNION ALL #
A diferencia que al usar union, cuando usamos la clausula UNION ALL, de la combinación de las filas no se eliminan las que son duplicadas y tampoco se realiza una verificación de la compatibilidad de datos.
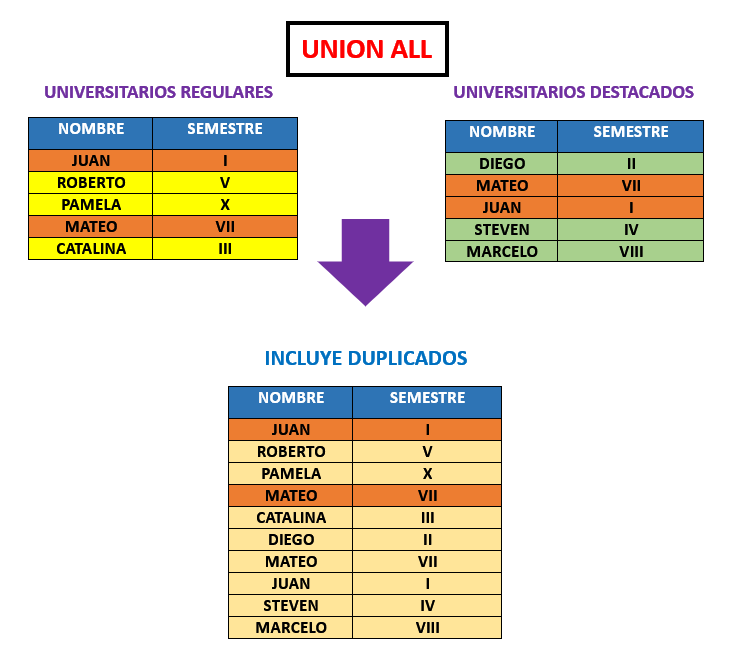
Como resultado si lo aplicamos a nuestros JOINS, nos devulve mas datos, donde podemos ver que estos se duplican.
En conclusión podriamos inferir que al combinar con UNION nos elimina las filas duplicadas y al usar UNION ALL de existir filas duplicadas las muestra.
INDICES #
Los indices en SQL vienen a ser una estructura de datos que mejoran la velocidad de la consultas y las operaciones de busquedas en un tabla. En terminos mas simples un indice nos permite acceder rapidamente a los registros de una tabla en función de los valores de una o mas columnas, de esta manera nuestras busquedas son mas eficientes.
INDICES ORDINARIOS - INDEX #
Los indices ordinarios o no unicos, crean indices que se pueden duplicar y ademas permiten incluir valores nulos. Solo usa el indice para buscar mas rapido pero obvia si existen o no duplicados.
Para crear un indice debemos usar CREATE INDEX y seguido el nombre a asignar, depues con ON especificaremos de que tabla queremos crear el indice y finalmente entre () debemos espeficar el campo especifico sobre el cual lo aplicaremos.
En este caso primero ejecutaremos una consulta que nos muestre todo de la tabla clientes Customers, donde el ContactName corresponda al de Hanna Moos.
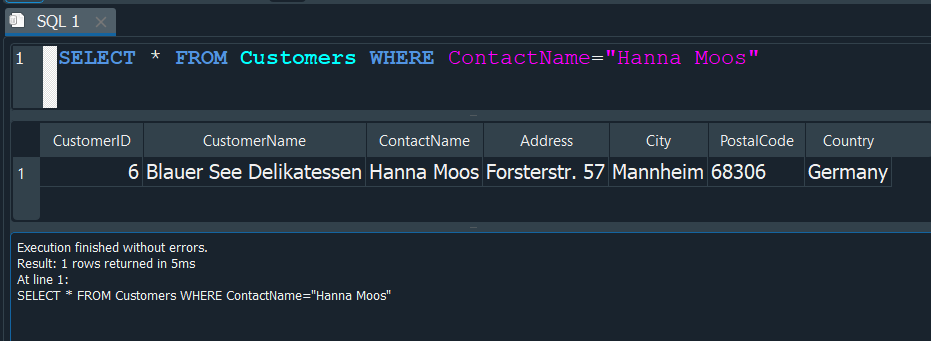
Podemos observar que nuestra consulta se ejecuta en un periodo de 5ms.
Lo siguiente que haremos es crear un indice en el campo ContactName de la tabla Customers.
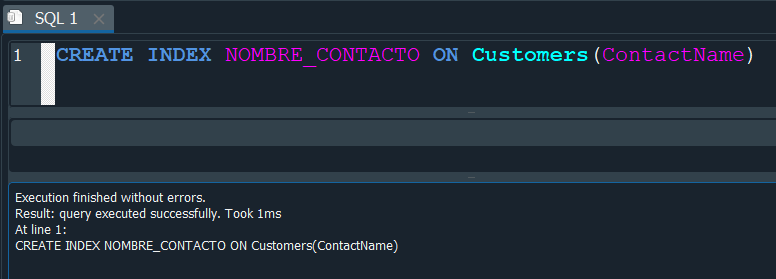
Ahora si volvemos a ejecutar la consulta anterior, observamos que la consulta esta vez solo tarda 1ms.
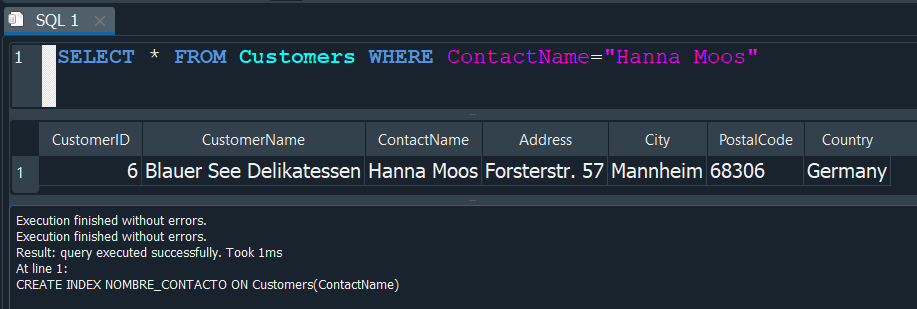
Esto no puede parecer notorio a consultas en una escala baja, pero de esta manera los INDICES nos dan una solución con la que podemos alivianar bastante el tiempo de consultas que son muy pesadas.
INDICES PRIMARIOS - PRIMARY KEYS #
Los indices primarios, son los ya mencionados PRIMARY KEYS, estos tienen como finalidad el permitirnos identidicar las filas de manera unica.
En este caso puntual si seleccionamos los datos de la tabla Customers, los indices primarios serian los valores correspondientes al CustomerID.
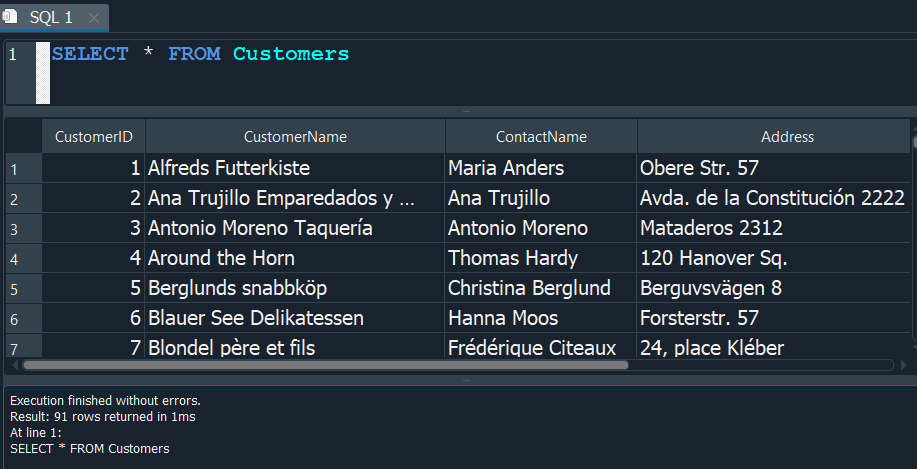
INDICES UNICOS - UNIQUE INDEX #
Este tipo de indice garantiza que los valores de una columna sean unicos en una tabla, esto implica que no puede haber duplicados en la columna y por ello al crearlos, ademas de mejorar el rendimiento de nuestras consultas verifica que no existan duplicados ni tampoco valores nulos. Puede aplicarse a uno o varios campos.
Para crear este tipo de indice es similar al ordinario, solo que debemos de agregar la palabra UNIQUE y lo vamos a crear en nuestra tabla Employees especificamente en los campos Firtsname y Lastname.
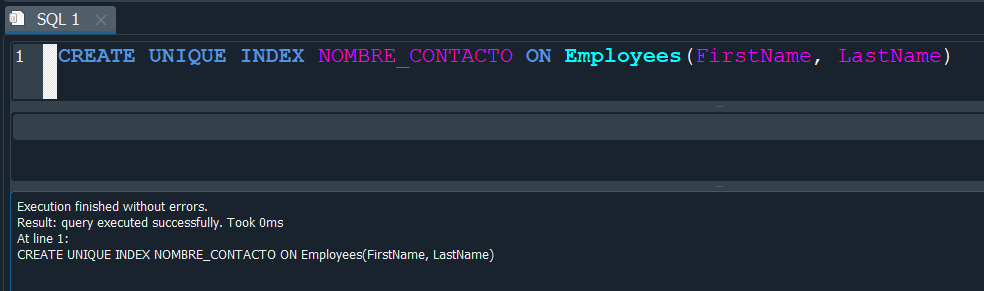
De esta manera lo que vamos a conseguir es que no se permita crear dos registros que tengan el mismo nombre Firtsnamey apellido Lastname. En tal sentido podemos crear registros que tengan distintos nombres y apellidos, pero si tratamos de insertar el mismo nombre y el mismo apellido, logicamente ya que dos personas no pueden tener los mismos datos correspondientes funciona como una especie de validación.
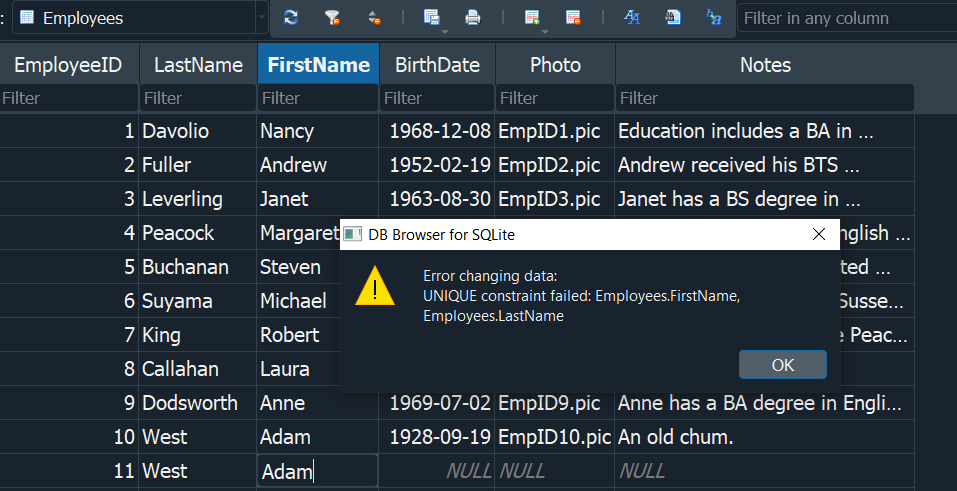
Concluimos que con este tipo de indice ademas que podemos tener un mejor rendimiento en nuestras consultas, tambien nos aseguramos de que no puedan existir valores duplicados. Si lo vemos practicamente en terminos reales es como cuando tratamos de registrarnos con un nombre de usuario y si este ya existe el sistema nos arroja un error, donde nos exige que intentemos con otros nombre de usuario.
Los indices consumen mucho espacio en disco, por ello si creamos demasiados indices podemos generar un impacto negativo, ademas que cuando se hace operaciones de alteracion de una tabla tambien se actualizan los indices y esto relentiza las operaciones de escritura. Por ello debemos de usar indices solo cuando sean necesarios, recomendablemente en consultas que realizamos constantemente o cuando tienen una alta cardinalidad en otras palabras cuando estemos trabajando con muchos indices.
Una ultima cosa es que si queremos borrar los indices, debemos usar DROP INDEX.
VISTAS #
Una vista es una representacio virtual de una tabla o de una combinación de tablas, por ello podemos pensar en las vistas como una especie de tabla virtual, estas ademas nos permiten simplificar las consultas especialmente cuando son muy complejas y trabajar sobre estas.
Supongamos que queremos trabajar sobre la tabla de clientes Customers, solo si estos son de la ciudad de Madrid o del pais de España, para ello tendriamos que realizar el filtro.
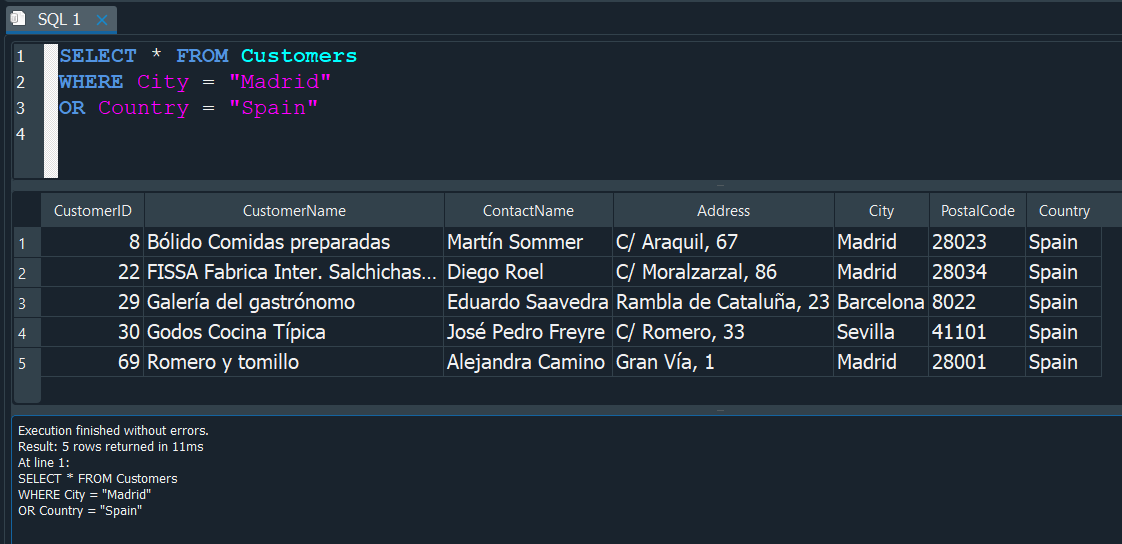
Ahora si nosostros quisieramos trabajar unicamente con estos datos, tendriamos que aplicar condicionales, joins o entre otras a esta misma consulta.
Pero lo que podemos hacer seria crear una vista, esto lo hacemos con CREATE VIEW mas el nombre de la vista que le queremos dar y seguidamente usamos AS para luego haces referencia a sobre que tabla crear nuestra vista. En este caso sobre el resultado de nuestra consulta anterior.
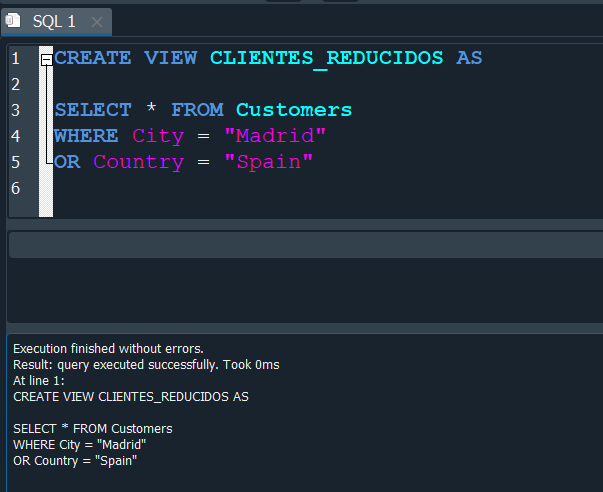
Vemos que ahora cambia de color, ya que ahora se almaceno como vista, y en consecuencia podemos trabajar directamente sobre ella como si fuera una tabla.
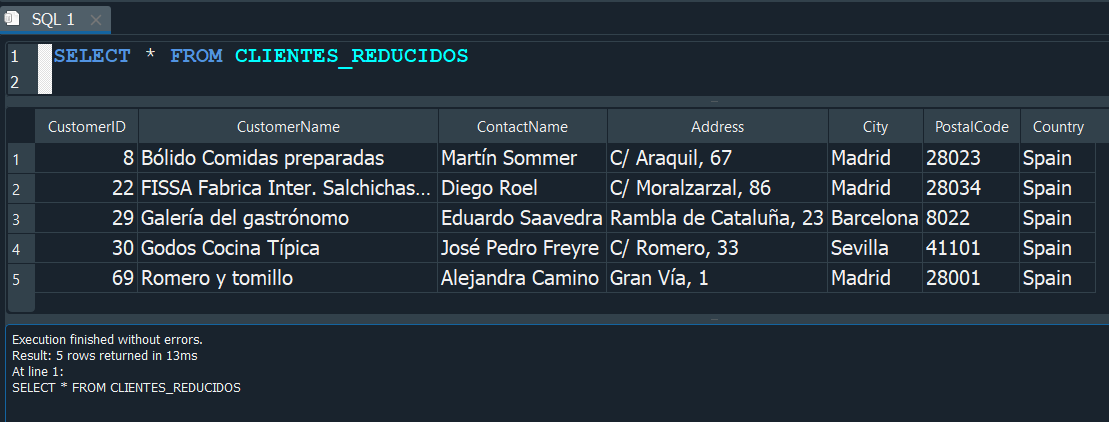
Ahora seguro puedes pensar que podemos usarlas todo el timpo y simplificarnos las tareas…
Pues no siempre por que debemos recordar que al ejecutar la vista, por detras se sigue ejecutando la consulta que la genero, por lo tanto realiza un consumo en disco y si lo aplicamos muchas veces tambien nos dara un problema de rendimiento.
Pero nos puede servir muchas ocasiones ya que nos simplifica el estar haciendo la misma consulta para un proposito, lo unico es que si las vamos a utilizar procuremos hacerlo de manera equilibrada.
Y una cosa mas para borrar una vista, debemos ejecutar DROP VIEW y el nombre de la vista.
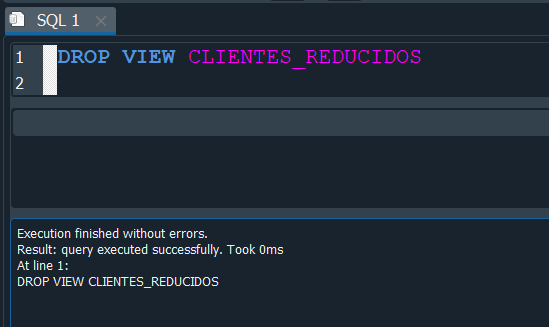
pero aqui una observación y es que si ejecutamos el comando nuevamente nos devuelve un error.
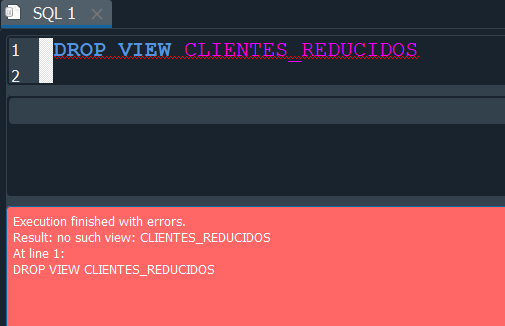
Por ello igualmente que cuando creamos una tabla se recomienda usar el IF EXISTS y de este modo verifica que la vista exista antes de borrarla.
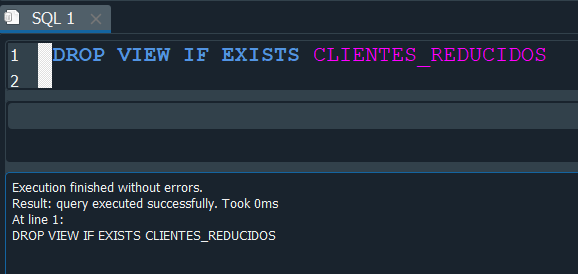
de esta forma ya no nos muestra el error.
BLOQUEOS #
Los bloqueos son los mecanismos de la bae de datos, que se utilizan para para controlar el acceso concurrente a la base de datos. Esto para evitar que en el proceso se realizen cambios conflictivos o se acceda al mismo tiempo a los datos.
Supongamos tenemos $500 dolares en nuestra cuenta bancaria, pero que pasaria si desde los lugares hacemos un retiro al mismo tiempo, pues lo que sucederia es que nuestra cuenta se quedaria con un valor negativo de -$500 y en vista que eso no puede suceder para ello es que suceden estos mecanismo de bloqueo.
Existen dos tipos de bloqueos:
BLOQUEOS COMPARTIDOS - SHARED LOCKS #
En este tipo de bloqueo nadie de los usuarios puede escribir, pero si pueden leer. En sintesis cuando nosotros estamos leyendo la base de datos ninguna de las otras conexiones puede escribir, pero si pueden leer.
BLOQUEOS RESERVADOS - RESERVED LOCKS #
Es este tipo de bloqueo se aplica cuando estamos escribiendo en la base de datos y en ese momento las otras conexiones no pueden escribir pero si pueden leer.
BLOQUEOS EXCLUSIVOS - EXCLUSIVE LOCKS #
En este tipo de bloqueos se da cuando mientras estamos escribiendo, las demas conexiones no puedan leer y tampoco puedan escribir, o en un caso mas especifico podemos manipularnos segun nos convenga.
TRANSACCIONES - BEGIN TRANSACTION #
Son una secuencia de operaciones que se consideran como una unidad logica, estas aseguran que todas las operaciones dentro de ellas se completen de manera exitosa o por el contrario se deshagan en caso de erro.
Para iniciar una nueva transaccion usamos BEGIN TRANSACTION o solo BEGIN.
Despues podemos hacer la alteración que queramos en las tablas de la base de datos, por ejemplo puedo cambiar el nombre a un producto, en este caso a Chang y renombrarlo como Refrescos.
Como son consultas separadas debemos hay que separarlas con un ;.
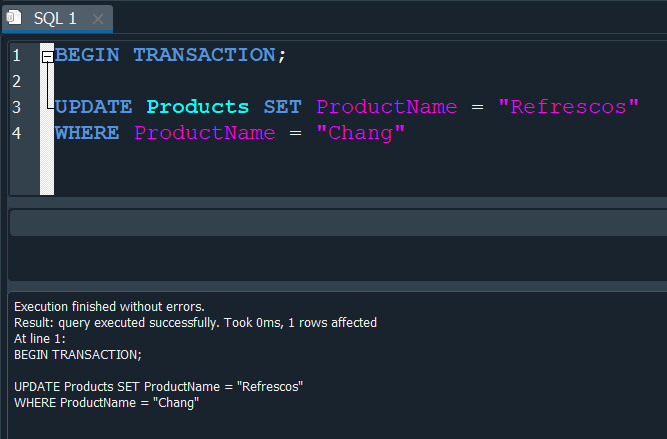
Despues de ejecutar la consulta y visualizamos que se cambia el nombre del producto.
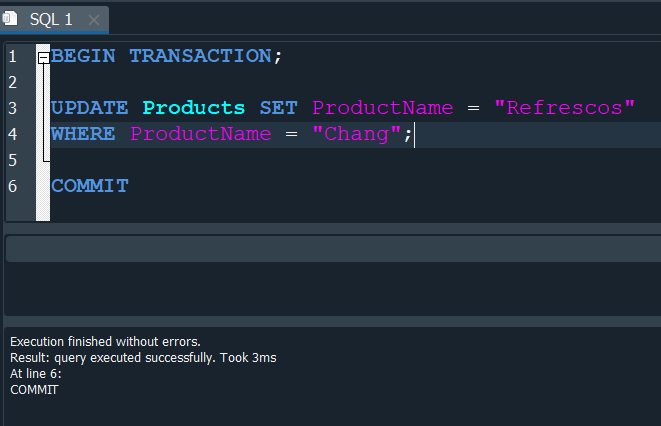
Es aqui donde entran a las transacciones ya que si bien realizamos el cambio, tenemos dos opciones la primera es que si estamos seguros de guardar los cambios ejecutemos COMMIT, pero en caso de existir un error y queramos volver a la acción anterior y no se efectuen ROLLBACK.
Primero ejecutamos COMMIT, de esta manera se efectuan los cambios.
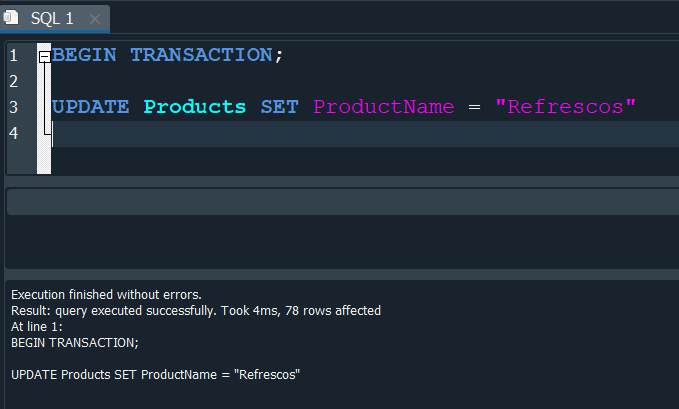
Ahora supongamos que por error modificamos los nombres de todos los productos.
Verificamos y efectivamente se realizaron los cambios.
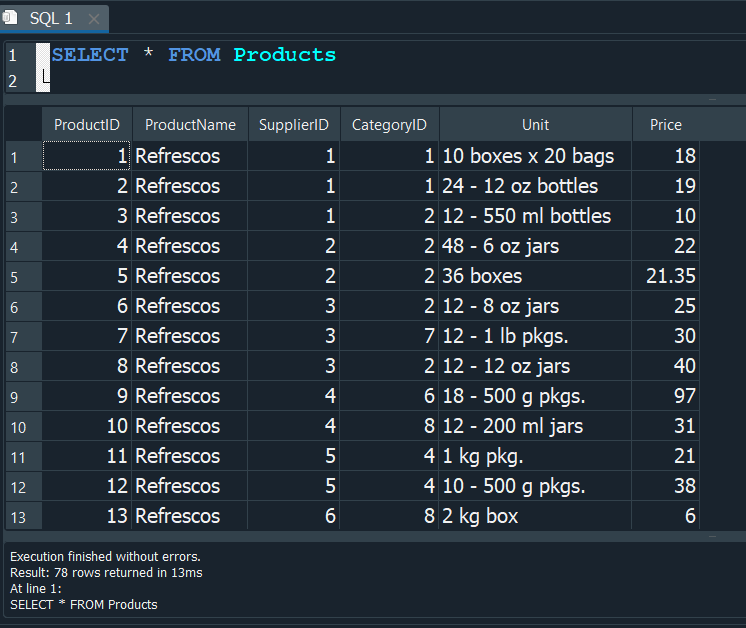
Podriamos pensar que hemos arruinado nuestra base de datos, pero ya que iniciamos una transacción, como mencionaba anteriormente con ROLLBACK, podemos restaurar los cambios, de modo tal que estos no se guarden.
Y de esta manera ya tenemos claro primero debemos iniciar una transacción con BEGIN, y una vez se haaya iniciado podemos ejecutar la consulta que queramos de modo tal que si despues queremos guardar los cambio ejecutar un COMMIT, y si de lo contrario queremos resturarlos usamos ROLLBACK.
PROCEDIMIENTOS ALMACENADOS #
Es un conjunto de instrucciones que se almancenan en la base de datos y que podemos ejecutarlos cuando queramos para reducir la repetición del codigo, mejora la seguridad por que se limita el acceso directo a la base de datos y aumenta el rendimiento ya que estas operaciones se ejecutan en el servidor de la propia base de datos.
sqlite3 se caracteriza por ser ligero de y facil implementación ya ejecuta como una biblioteca y por lo tanto no soporta procedimientos almacenados por que en principio no los necesita ya que se integra directamente en la aplicación que lo utiliza lo que facilita su portabilidad y en consecuencia es sencillo implementarlo en distintas plataformas y sistemas operativos.
Por lo tanto cuando queremos ejecutar procedimientos almacenados con sqlite3 lo hacemos desde el backend o lenguaje anfitrion a nivel de aplicación, usando las funciones del lenguaje y aunque estas funciones que podamos definir no son iguales a las de los procedimientos almacenados viene a ser la solución a este problema.
SQL Y PYTHON #
Como mencionamos anteriormente en el apartado anterior necesitamos de un lenguaje para ejecutar nuestras funciones definidas por el usuario y para ello usaremos nada mas y nada menos que Python.
FUNCIONES DEFINIDAS POR EL USUARIO - USER DEFINED FUNCTIONS #
Son funciones que podemos crear y utilizar dentro de nuestras consultas SQL. Estas funciones permiten ampliar las funcionalidades de SQLite realizando calculos o manipulaciones de datos especificos que no estas directamente disponibles en las funciones integradas.
Y para ello para definir estas funciones utilizaremos Python.
Comenzaremos importando la libreria de SQLite.
import sqlite3
Despues crearemos una función, en este caso una que nos devuelva el 20% de un valor que reciba como parametro.
def calcular_porcentaje(valor):
porcentaje = valor * 0.20
return porcentaje
Ya que tenemos nuestra función, ahora procederemos a crear una conexión con nuestra base de datos en este caso Northwind.db y la guardaremos en la variable conn. Ojo se debe espeficiar la ruta en donde tengas la db.
conn = sqlite3.connect("Northwind.db")
Ahora tenemos que registrar nuestra función en nuestra conexión conSQLite, para ello usamos el metodo create_function y como primer parametro especificamos el nombre que tendra la función en SQLite que puedes llamarla como quieras, en este caso la llamare Porcentaje, despues como segundo valor debemos espeficar el numero de parametros de nuestra función creada que en este caso es 1 y finalmente como tercer parametro nuestra función calcular_porcentaje.
conn.create_function("porcentaje", 1, calcular_porcentaje)
Una vez ya tengamos registrada nuestra función, ahora necesitamos crear es algo que nos permite hacer una consulta a la base de datos y obtener una respuesta con todos los datos ya procesados y para ello en Python, tenemos algo que se llaman cursores que nos devolveran los resultados ya formateados.
Asi que creamos un cursor y lo guardamos en la variable cursor.
cursor = conn.cursor()
Lo siguiente es ejecutar la consulta y eso lo hacemos con cursor.execute y dentro podemos ejecutar la consulta que queramos, para este caso vamos a hacer una consulta donde vamos a seleccionar el nombre de los productos de la tabla Products, el precio normal y ademas nuevamente el precio pero en este es donde vamos a ejecutar nuestra función porcentaje.
cursor.execute('SELECT ProductName, porcentaje(Price) FROM PRODUCTS')
Los resultados de la consulta vamos a almacenarlos en la variable resultados y para obtenerlos usaremos el metodo fetchall() que se utiliza para recuperar todas las filas del conjunto de resultados de una consulta.
En el caso en el que solo quisieramos recuperar solo una fila, usariamos fetchone(). Como en este caso queremos el resultado de varias filas usamos fetchall()
resultados = cursor.fetchall()
Finalmente cerrar el cursor y la conexión para liberar los recursos usados.
cursor.close()
conn.close()
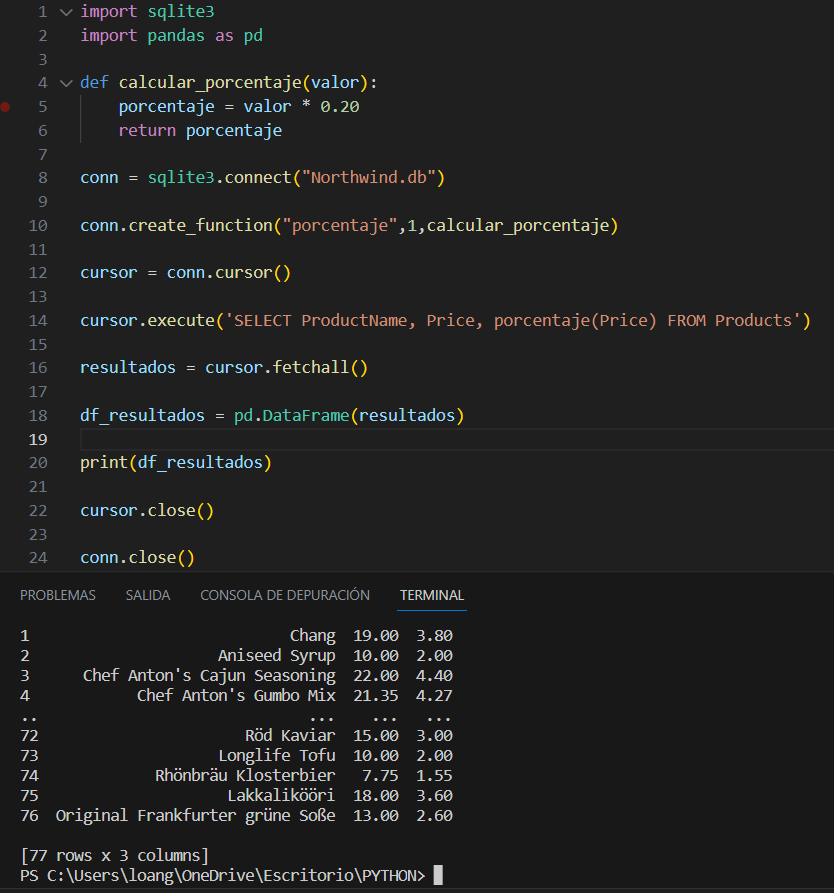
Y ahora si imprimimos los resultados, nos lo devolvera en crudo, de tal forma que no sera bien legible. Para solucionar este problema usaremos otra libreria de Python llamada pandas y con ellas vamos a exportar el resultado en un dataframe que basicamente nos permitira mostrar la información en una especie de tablas.
Por lo tanto nuestro codigo completo nos quedaria asi:
import sqlite3
import pandas as pd
def calcular_porcentaje(valor):
porcentaje = valor * 0.20
return porcentaje
conn = sqlite3.connect("Northwind.db")
conn.create_function("porcentaje", 1, calcular_porcentaje)
cursor = conn.cursor()
cursor.execute('SELECT ProductName, Price, porcentaje(Price) FROM PRODUCTS')
resultados = cursor.fetchall()
df_resultados = pd.DataFrame(resultados)
print(df_resultados)
cursor.close()
conn.close()
Al ejecutar nos da como resultado de una majera mas legible los resultados.
Todo esto que acabamos de hacer es una transacción, ya que estas se inician por el lenguaje anfitrion, tras bambalinas lo que esta haciendo Python es hacer un BEGIN automaticamente, entonces una vez que realizamos toda la conexión si queremos que se guarden los cambios hay que usar exacto un COMMIT y de esta manera hubieramos ejecutado correctamente la conexión.
Pero existe una manera mas sencilla y optima para hacer exactamente lo mismo, esto nos ayudaria a simplificar nuestro codigo y evitar estar cerrando estas conexiones. Para esto tendriamos que usar with y manejar los errores con un Try Catch.
Voy a explicar como funciona y por que es mas optimo usar esta opción - aunque en el curso de Python veremos esto a detalle:
Bueno principalmente es mas optimo, puesto que cuando usamos with para conectarnos a la base de datos nos va a garantizar que la conexión se cierre automaticamente al finalizar el bloque de codigo y nos asegura que los recursos de la conexión que establecimos se liberen correctamente aunque ocurran exepciones.
Pero para estar seguro tambien usaremos un Try Catch, donde manejaremos las exepciones en el caso pueda existir alguna:
Como primera exepción usamos sqlite3.Error que capturara los errores especificos de SQLite de haberlos y nos mostrara a cual corresponde en pantalla.
Despues una exepción general con Exception, si es que el problema no se da necesariamente con SQLite y de esta manera tambien nos lo reporte al ocurrir.
import sqlite3
import pandas as pd
def calcular_porcentaje(valor):
porcentaje = valor * 0.20
return porcentaje
Try:
with sqlite3.connect("Northwind.db") as conn:
conn.create_function("porcentaje", 1, calcular_porcentaje)
cursor = conn.cursor()
cursor.execute('SELECT ProductName, Price, porcentaje(Price) FROM PRODUCTS')
resultados = cursor.fetchall()
df_resultados = pd.DataFrame(resultados)
print(df_resultados)
except sqlite3.Error as e:
print("Error en la base de datos: ", e)
except Exception as e:
print("Error global: ", e)
Ahora para cerrar el cursor, vamos a realizar un ejemplo un poco mas complejo igual desde Python donde de nuestra base de datos trataremos de obtener los 3 empleados que generaron mas ingresos en general.
Para ello primero armaremos la estructura de nuestro codigo y importaremos la libreria matplotlib para visualizarlo los resultados graficamente y esta vez como estamos usando pandas vamos a usar una función que nos permite leer una consulta SQL la cual es pd.read_sql_query
import sqlite3
import pandas as pd
import matplotlib.pyplot as plt
consulta = '''
'''
with sqlite3.connect("Northwind.db") as conn:
resultado = pd.read_sql_query(query, conn)
resultado.plot(x=, y=, kind="bar", figzise=(10,5), legend=False)
plt.title("Empleado que genero mas Ingresos")
plt.xlabel("Nombre Empleado")
plt.ylabel("Monto Total Vendido")
plt.xticks(rotation=45)
plt.show()
Vamos a explicarlo paso a paso:
Con pd.read_sql_query que recibe dos parametros, en el primero lo que hacemos es que directamente le pasamos la consulta que queramos ejecutar y como segundo parametro la conexión que esta almancenada en conn.
Despues usamos la libreria matplotlib.pyplot para crear un plot que se refiere a crear un grafico, donde con x indicaremos y indicaremos los valores bajo los cuales se creara, que aun no los definimos, despues con kind indicamos el tipo de grafico que queremos que tenga, en este caso en barras, figzise para indicarle el tamaño que tendra nuestro grafico y despues con legend si queremos que tenga una leyenda, en este caso no quiero que se vea por ese le pongo false.
Despues con plt.title, le damos un nombre a nuestra grafica, plt.xlabel para ponerle un nombre en el eje X y plt.ylabel lo mismo para el eje Y. Despues con xticks le decimos que el nombre del eje X, tenga una rotación de 45 grados para que los nombres no salgan uno encima de otro.
Finalmente con plt.show() le decimos que nos muestre el grafico.
Ahora en lo que respecta a nuestra consulta, como queremos seleccionar el empleado que genero mas ingresos, primero vamos a seleccionar los datos del empleado y la suma de la cantidad vendida Quantity referente a la tabla OrderDetails por el Precio correspondiente a la tabla Products esto de la tabla Employees

Despues vamos a aplicar un JOIN y buscaremos las coincidencias de las tablas partiendo de Employees hasta la tabla OrderDetails donde tenemos la cantidad y a su vez hasta la tabla Products donde tenemos el precio.
Esto aunque puede parecer complicado lo haremos basandonos en los ID.

Despues solo debemos agruparlo basandonos en el EmployeeID ya que justamente queremos saber el empleado que genero esos ingresos y finalmente debemos ordenarlo por el total_vendido y establecer un LIMIT de los tres primeros.
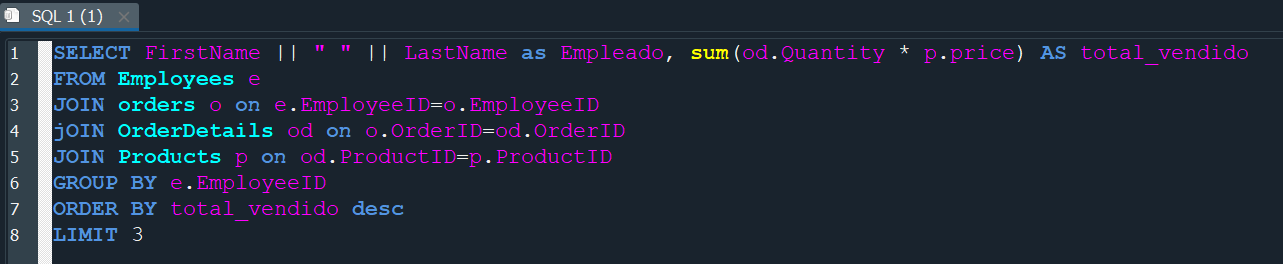
Finalmente debemos añadir esa consulta a nuestra variable consulta en nuestro codigo y completar tambien los parametros que faltaban en el plot donde x=Empleado y y=total_vendido.
import sqlite3
import pandas as pd
import matplotlib.pyplot as plt
consulta = '''
SELECT Firstname || "" || LastName as Empleado, SUM(od.Quantity * p.Price) AS total_vendido
FROM Employees e
JOIN Orders o ON e.EmployeeID = o.EmployeeID
JOIN OrderDetails od ON o.OrderID = od.OrderID
JOIN Products p ON od.ProductID = p.ProductID
GROUP BY e.EmployeeID
ORDER BY total_vendido DESC
LIMIT 3
'''
with sqlite3.connect("Northwind.db") as conn:
resultado = pd.read_sql_query(query, conn)
resultado.plot(x=, y=, kind="bar", figzise=(10,5), legend=False)
plt.title("Empleado que genero mas Ingresos")
plt.xlabel("Nombre Empleado")
plt.ylabel("Monto Total Vendido")
plt.xticks(rotation=45)
plt.show()
El codigo en python nos quedaria de esta manera, ahora solo debemos ejecutarlo y obtendremos graficamente los tres empleados que generaron mas ingresos a la empresa.
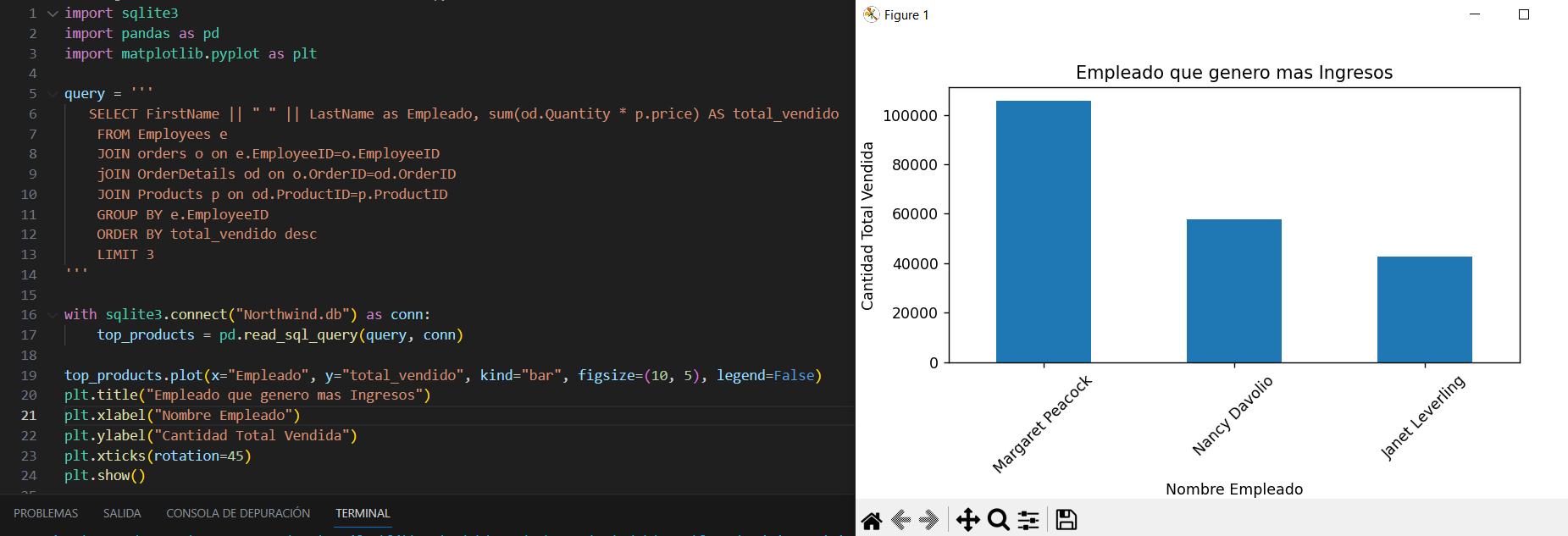
Y esto seria todo con respecto al curso de SQL, ahora si estas listo para administrar cualquier base de datos SQL, espero haberte ayudado. 😃
Conmigo sera hasta la proxima vez 😄.
Comments